- Traditional Approach : image denoising, high-level vision tasks는 별개로 다루어짐
- This Paper Approach : two jointly (동시에 다루기), explore the mutual influence (서로 간의 영향력을 탐구)
논문에서 기여한 점
1. Image Denoising을 위한 Convolutional Neural Network을 제안 (state-of-the art 성능)
2. Image Denoising, various high-level tasks 두 개의 모듈을 계단식으로 만들고, back-propagation을 통해 denoising network만 joint loss를 통해 업데이트 하는 네트워크 솔루션을 제안함
3. high-level vision 정보로 denoising network는 더 시각적으로 매력적인 결과를 생성함
1. Introduction
computer vision의 흔한 접근은 low-level vision 문제들(image restoration, enhancement)부터 high-level vision 문제까지 독립적으로 하나의 주제에 대한 문제 해결 방법을 연구해왔습니다.
이 논문에서는 low-level과 high-level computer vision 문제를 하나의 통합된 framework로 해결 하는 관점을 제안하였습니다.

Image denoising 문제는 대표적인 low-level vision 문제로 이미지에 포함되어있는 노이즈를 제거하는 것입니다.
대표적인 Computer Vision으로 해결 방법 논문으로 아래 논문들이 있습니다.
1. K-SVD : An algorithm for designing overcomplete dictionaries for sparse representation.
2. Color image denoising via sparse 3d collaborative filtering with grouping constraint in luminance-chrominance space.
3. Non-local sparse models for image restoration.
4. Nonlocally centralized sparse representation for image restoration.
5. Weighted nuclear norm minimization with application to image denoising.
6. Patch group based nonlocal self-similarity prior learning for image denoising.
Deep learning 기반 Image denoising 논문은 아래와 같습니다.
1. Extracting and composing robust features with denoising autoencoders.
2. Image denoising: Can plain neural networks compete with bm3d?
3. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections.
4. A flexible framework for fast and effective image restoration.
5. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising.
6. U-net: Convolutional networks for biomedical image segmentation.
이 논문의 저자는 U-Net에 영감을 얻어 Image denoising을 위한 CNN network를 구성하였고 state-of-the-art 성능을 냈습니다.
가장 인기 있는 image denoising 알고리즘은 mean square error (MSE)를 최소화하여 이미지를 재구성합니다.
하지만 이는 noise가 없어지면서 image quality의 저하를 가져옵니다. (과도하게 스무딩 되며 texture가 사라짐)
저자는 image denoising과 high-level vision network를 연결하는 cascade architecture를 제안하였고
image reconstruction loss와 high-level vision loss 를 동시에 최소화하도록 joint loss를 구성하였습니다.
image semantic 정보를 가이드로 삼아 denoising network가 이미지의 Quality를 높이고 사람 눈에도 보기 좋은 output을 만들어 내도록 했습니다.
기존에도 high-level vision 작업들을 진행할 때 노이즈가 많은 data가 있으면 image restoration을 수행하는 preprocessing 과정을 거쳤습니다. 이런 preprocessing 작업을 하는 이유는 노이즈가 많은 data로 진행하면 결과가 좋지 않기 때문입니다.
여기서 저자는 cascaded network를 joint loss와 함께 학습시킨 network는 image sematic 가이드를 통해 denoising network의 성능을 높일 뿐만 아니라 높은 수준의 high-level vision 작업의 정확도를 크게 향상했다고 합니다.
2. Method
먼저 여기 논문에서 사용하는 denoising network를 소개하고 image denoising 모듈과 high-level vision 모듈간의 관계를 자세하게 설명할 것입니다.
2.1 Denoising Network
input : noisy image, output : reconstructed image
이 네트워크는 Downsampling과 Upsampling을 통해 feature 축소 및 확장을 수행합니다.
Downsampling 및 Upsampling 연산의 각 쌍은 feature 표현을 새로운 공간 scale로 가져와 전체 network가 다른 scale에서 정보를 처리할 수 있습니다.
input은 Feature Encoding을 진행하고 해당 scale을 Downsampling하고 Feature Encoding을 진행하게 됩니다.
output은 Feature Decoding을 진행하고 해당 scale을 Upsampling을 하고 Feature Decoding을 진행합니다.
Downsampling과 Upsampling 단계는 pair로 이루어져 있고 중첩하여 feature 표현의 공간적 규모가 더 깊은 네트워크를 구축할 수 있으므로 일반적으로 복원(restoration) 성능이 향상됩니다.
하나의 Feature Encoding module은 매 scale마다 존재 하도록 디자인했습니다. Feature Encoding은 하나의 convolutional layer와 하나의 residual block으로 이루어집니다. Fig. 2 (b)
매번 Convolutional layer 다음으로 batch normalization을 수행하고 ReLU를 합니다.
4개의 convolutional layer는 각각 128, 32, 32, 128 kernel이고 3x3, 1x1, 3x3, 1x1 filter사이즈입니다. output은 첫 번째 convolutional layer와 skip connection으로 연결되어 있고 마지막 convolutional layer와 element-wise sum을 수행합니다.
Feture Decoding module도 4개의 convolutional layer로 구성 되어 있고 256, 64, 64, 256개의 kernel과 filter는 3x3, 1x1, 3x3, 1x1로 이루어져 있습니다. Encoder과 동일하게 skip connection이 적용되어 있습니다. Fig. 2 (c)
Feature Downsampling & Upsampling :
Downsampling과 Upsampling factor는 2를 사용 하였습니다. 두 가지 실험을 하였는데 (1) max pooling with stride 2 (2) convolutions with stride 2입니다. 두 가지 모두 denoising performance는 비슷했다고 합니다. 계산 효율성을 위해 (2) 번을 선택했다고 합니다. Upsampling으로는 deconvolution을 4x4 kernel을 이용하여 하였습니다.
2.2 When Image Denoising Meets High-Level Vision Tasks
Propose
1. reconstruct visually pleasing results guided by the high-level vision information, as the output of the denoising network
2. attain sufficiently good accuracy across various high-level vision tasks, when trained for only one high-level vision task
결국 high-level vision 정보를 가지고 denoising network의 성능을 높이고, 하나의 high-level vision task로 학습을 했어도 다른 high-level task들을 붙여도 높은 성능을 보여준다는 점입니다.
cascaded
동사 [V + adv. / prep.]
- 1.자동사
폭포처럼 흐르다 - Water cascaded down the mountainside.
- 물이 산허리를 폭포처럼 흘러내렸다.
- 2. 자동사격식
풍성하게 늘어지다 [매달리다] - Blonde hair cascaded over her shoulders.
- 풍성한 금발머리가 그녀의 어깨 위로 늘어져 있었다.
cascaded의 뜻은 폭포처럼 흐르다, 풍성하게 늘어지다인데 그냥 연결된? network라고 이해하시면 될 것 같습니다.
제안하는 cascaded network는 Fig 3. 에 잘 정리가 되어 있습니다.
Noise input이 Denoising Network에 적용되고 denoised result를 High-Level vision task를 담당하는 network에 들어가서 high-level vision task output이 나오게 됩니다.
Training Strategy : high-level vision task network는 noise 없는 input으로 well-trained 된 weight로 초기화를 합니다. 그리고 weight를 고정시킵니다. (weight 학습하지 않음)
Denoising network의 weight만 back-propagation을 통해 계산된 error만큼 업데이트하게 됩니다.
Super-resolution [Johnson et al., 2016]에서 사용된 perceptual loss의 학습 방법과 유사합니다.
이러한 Training Strategy을 선택한 이유는 다양한 High-level vision task에 대한 일반성을 잃지 않고 denoising network를 충분히 견고하게 만들기 위함입니다. 보다 구체적으로, 하나의 high-level vision task에 대해 훈련된 denoising network는 network를 미세 조정하지 않고도 다른 high-level network에 직접 연결할 수 있습니다.
Denoising network는 high-quality perceptual & semantically faithful results를 얻을 수 있습니다. (좋은 결과가 나온다는 얘기를 고급스럽게 쓴 것입니다ㅎㅎ)
Loss : Denoising을 학습할 때 쓰는 Reconstruction Loss는 mean squared error (MSE)를 사용하는데 denoising network의 output과 noiseless image(ground truth) 간의 MSE를 구하는 것입니다.
High-Level Vision Tasks의 loss는 cross-entropy loss를 사용하는데 예측된 label과 ground truth label 간의 cross-entropy loss를 구합니다.
Loss는 결국 D Loss와 H loss * lamda 값의 합으로 이루어집니다. lamda값으로 H loss의 weight를 조절합니다.
3 Experiments
3.1 Image Denoising
noisy 한 input을 만들기 위해 identically distributed Gaussian noise with zero mean을 original image에 추가합니다.
처음에 그냥 본인들의 network 성능을 검증하기 위해 lamda를 0으로 하고 SGD를 사용하고 batch size를 32로 하여 input patch를 48x48 pixel로 하고 학습을 진행합니다. learning rate = 10^-4이고 500,000 iteration이 지나고 10을 나눠줍니다. 총 1,500,000 iteration을 학습하고 종료합니다.
자기네 network의 성능이 다른 네트워크에 비해 PSNR이 높다라고 얘기하는 표입니다. 조금씩 그래도 성능이 나오고 있습니다. Kodak dataset으로 평가한 결과입니다.
3.2 When Image Denosing Meets High-Level Vision Tasks
여기서 실험한 High-level vision task는 image classification, semantic segmentation 두 가지입니다.
image classification network로 VGG-16을 사용하였고 DeepLab-LargeFOV를 semantic segmentation network로 사용하였습니다. DeepLab은 현재 V3+까지 나와있습니다.
더 궁금하신 분은 제 포스팅을 참고 부탁드립니다~
Semantic Segmentation, DeepLab V3+ 분석
Semantic Segmentation, DeepLab V3+ 분석
Semantic Segmentation, DeepLab V3+ 분석 Semantic Segmentation과 Object Detection의 차이! semantic segmentation은 이미지를 pixel단위로 분류합니다. 아래 고양이의 발쪽 픽셀을 고양이 그 아래 잔디 pix..
mypark.tistory.com
Image classification task는 ILSVRC2012 dataset으로 실험을 하였고 lamda는 0.25로 학습을 진행하였습니다.
Semantic segmentation task는 Pascal VOC2012 dataset으로 실험을 하였고 lamda는 0.5로 학습을 진행하였습니다.
sematic segmentation network의 도움을 받아 denoising network를 학습했을 시에 높은 PSNR이 나오지는 않지만 Kodak dataset에서 눈으로 보았을 때 detail을 더 보존하고 있고 texture가 더 좋은 것을 알 수 있습니다.
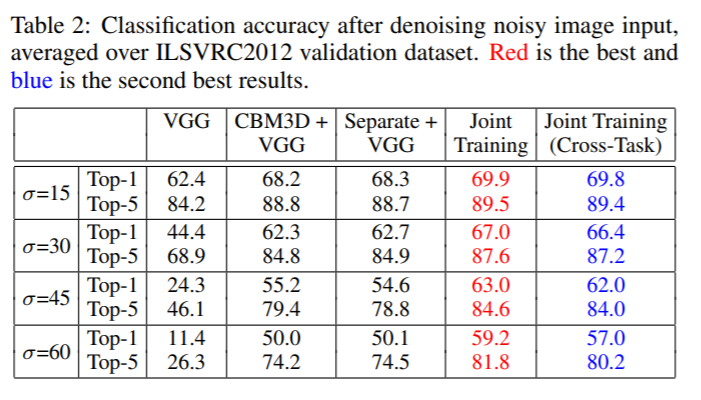
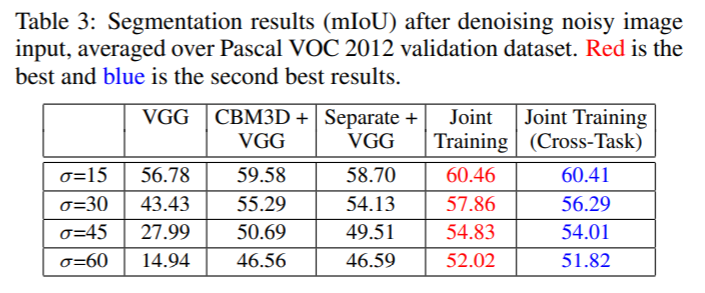
Cases
- noisy image를 곧바로 VGG에 넣을 때 classification accuracy 결과입니다. (base line)
- noisey image를 CBM3D로 넣고 나온 결과를 VGG에 넣었을 때 classification accuracy 결과입니다.
- denoising network를 lamda를 0으로 해서 따로 학습하고 그 결과를 VGG에 넣어서 나온 classification accuracy 결과입니다. sigma가 45일 때 CBM3D보다 Top-1에서 떨어지는 것을 볼 수 있습니다.
- 이 논문에서 제안하는 cascade networks를 사용하여 학습한 결과입니다. 모든 결과에서 가장 좋은 성능을 내고 있습니다.
- denoising network를 classification network와 연결하여 학습을 진행하고 나서 semantic segmentation network를 연결했을 때 성능을 본 것이 Joint Training (Cross-Task)입니다. Table 3는 그 반대로 했을 때 결과입니다. 이렇게 High-Vision task network를 바꿔껴도 성능상에 큰 차이가 없다는 것을 강조하고 싶은 것 같습니다.
이것으로 When Image Denoising Meets High-Level Vision Tasks: A Deep Learning Approach 논문 리뷰를 해 보았습니다. high-level tasks와 denoising network를 각각 학습하던 것을 한 번에 학습하면서 두 마리 토끼를 다 잡는 획기적인 방법을 제안한 것 같습니다. 실제 실생활에 사용하는 image에서 효과가 있을지는 모르겠지만 high-level vision information이 denoising 성능에 영향을 준다는 것은 어느 정도 효과가 있을 것으로 보입니다. (실제 test는 해봐야겠지만요)
질문 있으시면 언제든지 달아주시면 답변드리겠습니다~ 감사합니다.
'Artificial Intelligence > Paper' 카테고리의 다른 글
| Optical Flow Estimation using a Spatial Pyramid Network 리뷰 (SpyNet) (1) | 2023.05.25 |
|---|---|
| Enhanced Deep Residual Networks for Single Image Super-Resolution 리뷰 (0) | 2021.12.28 |
| Semantic Segmentation, DeepLab V3+ 분석 (0) | 2021.08.03 |



댓글