https://arxiv.org/abs/1707.02921
Enhanced Deep Residual Networks for Single Image Super-Resolution
Recent research on super-resolution has progressed with the development of deep convolutional neural networks (DCNN). In particular, residual learning techniques exhibit improved performance. In this paper, we develop an enhanced deep super-resolution netw
arxiv.org
0. Abstract
최근 연구(2017년)들은 deep convolution nerual networks(DCNN)을 기반으로 진행이 되고 있습니다.
이 논문에서 제한하는 것은 enhanced deep super-resolution network (EDSR)로 SR method중 state-of-art를 기록했습니다. Conventional residual network 에서 필요없는 모듈들을 제거하고 최적화를 하여 이러한 성능을 냈다고 합니다.
model parameter를 확장하여 성능의 추가 개선을 가져왔고 training 과정의 안정화도 가져왔습니다.
또한 multi-scale deep super-resolution system(MDSR)과 training 방법을 제안하였고, 단일 모델에서 다양한 upscaling 요소의 고해상도 이미지를 재구성할 수 있습니다.
NITRE2017 Super-Resolution Challenge에서 승리하였습니다.
1. Introduction
Image super-resolution (SR) prblem에서 특히 single image super-resolution (SISR)은 계속해서 관심이 늘어나는 연구 분야 입니다.
SISR의 목적은 $I^{LR}$ (single low-resolution)로 부터 $I^{SR}$ (high-resolution) image를 얻는 것입니다.
많은 연구에서 $I^{HR}$ (high-resolution) 이미지를 bicubic downsample하여 얻은 이미지를 $I^{LR}$로 정의하고 사용합니다. 이후 화질을 떨어트리는 요소들로 blur, decimation (다운샘플링), noise를 주로 사용합니다.
1. nerual network의 reconstruction 성능은 minor architectural 변화에 민감하게 변합니다. 또한 동일한 모델을 다른 initialization와 training 기술을 사용하면 다른 성능을 얻게 됩니다.
※ 주의깊게 디자인된 모델 구조와 정교한 optimization 방법이 매우 중요
2. 기존의 대부분의 SR 알고리즘은 SR에서 서로 다른 스케일 간의 상호 관계를 고려하고 활용하지 않고 서로 다른 문제로 취급해 왔습니다. example) x2, x4를 각각 다른 문제로 취급
그래서 이러한 알고리즘들은 스케일에 맞는 network를 각각 훈련하고 처리해야 했습니다.
VDSR [1]은 여러가지 scale을 공동으로 처리할 수 있는 single network 입니다. 다양한 scale로 training한 VDSR 모델은 성능을 상당히 올렸고 scale별로 training한 모델보다 뛰어난 성능을 보였습니다.
이것은 scale-specific하게 training을 할 필요가 없다는 것을 의미합니다. => input으로 bicubic interpolated된 image가 필요하여 computation time과 memory가 heavy (이 부분은 조금 이해가되지 않음. bicubic이 그렇게 heavy한 알고리즘은 아님, 추가 논문 리뷰 예정)
SRResNet [2]은 VDSR [1]이 가지고 있던 computation time과 memory issue를 해결 하면서 좋은 성능을 보였습니다.
SRResNet은 ResNet 구조를 많은 수정 없이 가져와서 만든 모델입니다.
ResNet은 high-level computer vision problem (image classification, detecton) 문제를 풀기위해 제한된 구조로 SR같은 low-level vision에는 최선의 솔루션이 아닐 수 있습니다(suboptimal).
EDSR에서 개선점
1. 이러한 문제를 해결하기 위해서 SRResNet 네트워크를 기반으로 이것을 분석하고 필요없는 모듈을 제거하여 네트워크 구조를 간결하게 하였습니다. 모델이 복잡하면 네트워크를 학습하는 것은 더 중요해지게 됩니다.
2. 다른 scale에서 훈련된 모델로부터 지식을 전달하는 모델 training 방법을 조사하였습니다. Training중에 scale-independent한 정보를 활용하기 위해, low-scale에서 pretrained된 모델들을 high-scale 모델들을 train할 때 사용합니다. 게다가 새로운 multi-scale architecture를 제안하는데 이 것은 서로 다른 scale의 대부분의 매개 변수를 공유하는 구조입니다.
3. 제안된 multi-scale 모델은 여러개의 scale 모델들을 사용하는 모델에 비해 훨씬 적은 매개 변수를 사용하지만 비슷한 성능을 보여줍니다.

2. Related work
Advance works : aim to learn mapping functions between $I^{LR}$ and $I^{HR}$ image pairs.
Learning 방법으로는 neighbor embedding, sparse coding, patch spaces and learns the corresponding functions.
VDSR[1] => first introduced the residual network for training much deeper network architectures and achieved superior performance.
Mao et al. [3] -> Encoder-decoder network와 symmetric skip connection을 제안
nested skip connection은 빠르고 향상된 convergence를 보여줌.
많은 deep learning based super-resolution algorithm은 input image를 bicubic interpolation을 통해 network에 fed해왔습니다. 그 다음 연구로는 interpolated된 image를 입력으로 사용하는 대신, 네트워크의 맨 끝 부분에서 upsampling 모듈을 훈련시키는 연구가 제안되었습니다. 이 방법은 feature의 사이즈가 줄기 때문에 모델의 capacity를 잃지 않고 연산양을 많이 줄일 수 있습니다. 하지만 단점으로는 VDSR[1]과 같이 하나의 network로 multi-scale을 다룰 수 없게 됩니다.
이 연구에서는 multi-scale 훈련과 computational 효율성의 딜레마를 해결하였습니다. 각 scale에 대해 학습된 feature의 상호 관계를 활용할 뿐만 아니라 다양한 scale에 대한 고해상도 이미지를 효율적으로 재구성하는 새로운 multi-scale model을 제안합니다. 적절한 training 방법을 개발하여 단일 및 다중 scale 모델 모두에 대해 여러 scale을 사용합니다. (이 부분은 글로는 이해가 힘들어 Chapter 3에서 자세히 설명)
Zhao et al. [4]는 L2 loss를 사용하는게 PSNR이나 SSIM에 더 나은 성능을 제공한다는 걸 보증하지 못한다고 주장했습니다. 저자는 L2로 학습했을 때보다 L1에서 더 개선된 성능을 얻었다고 합니다.
3. Proposed Methods
3.1. Residual blocks
최근에 residual network는 low-level 부터 high-level task까지 computer vision 문제들에서 좋은 성능을 내고 있습니다.

Fig. 2에서는 각각의 network에서 original ResNet과 SRResNe, 그리고 Proposed network를 볼 수 있습니다.
Batch normalization layer가 없어진 것을 볼 수 있습니다. 이 계층은 feature들을 정규화 하기 때문에 feature들의 범위 유연성을 제거(전체적으로 평준화 됨)하기 때문에 제거하는 것이 좋습니다.
※ 제 경험상으로 batch normalization은 u-net 구조에서는 별로 효과가 없음
이러한 간단한 수정이 성능을 크게 향상시키는데 자세한 것은 Sec. 4에서 말씀 드리겠습니다.
또한 batch normalization layer는 이전의 convolution layer와 동일한 양의 메모리를 사용하기 때문에 GPU 메모리 사용량도 상당히 감소됩니다. Batch normalization layer가 없는 Proposed된 모델은 SRResNet과 비교하여 메모리가 약 40%가 절약됩니다. 따라서 제한된 computational resources 내에서 기존 ResNet 구조보다 성능이 우수한 더 큰 모델을 구출 할 수 있게 되었습니다.
3.2. Single-scale model
Network 모델의 성능을 개선하는 방법 중 가장 간단한 것은 parameter의 수를 증가시키는 것입니다. 그러나 특정 수준 이상으로 feature map의 수를 늘리면(parameter) training이 수치적으로 불안정해집니다.
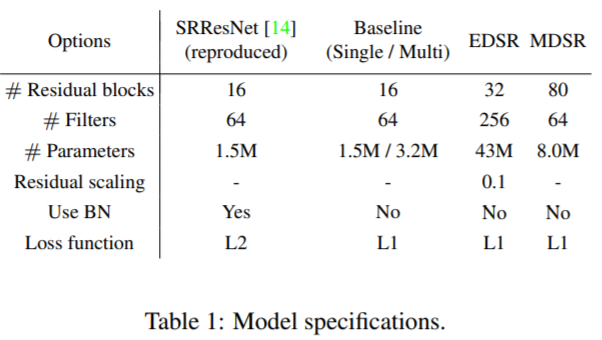
single-scale baseline model은 아까 위에서 봤던 SRResNet과 유사한 residual block을 사용합니다. 제안하는 resBlock은 ReLU activation layer가 residual block 밖에 존재하지 않습니다. 또한 residual scaling layer를 가지고 있지 않습니다. 왜냐하면 각 convolution layer의 feature map으로 64개만 사용하기 때문입니다.
(The number of layers) B = 32, (the number of feature channels) F = 256 with a scaling factor 0.1
모델을 학습 할 때 upsampling factor x3, x4을 학습하기 위해 x2배로 pre-trained network로 model parameter를 초기화 한 후 진행을 합니다. 이 pre-training 전략은 training을 빠르게 만들고 성능도 개선 됨을 확인하였습니다.
※ 각 scale의 학습된 parameter를 가지고 다른 scale에 사용할 수 있다는 게 매력적, 실제로 각 scale 별로 상호 관계가 있다는 것을 그래프로 증명

3.3. Multi-scale model
저자는 superresolution이 여러 scale들이 연관된 task라고 결론을 지었습니다. (VDSR에서 idea를 얻은 듯)
multi-scale 모델은 single main branch + (B = 16 residual blocks)으로 이루어 져 있으며 대부분의 parameter들은 다른 scale에도 공유가 됩니다.
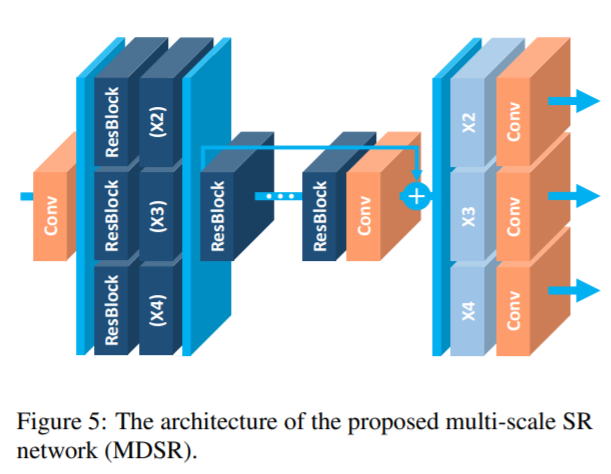
multi-scale 구조에서, 여러개의 scale을 super-resolution에서 처리하기 위해 scale-specific 처리 모듈을 도입하였습니다.
pre-processing 모듈은 다른 scale의 입력 이미지들로 부터의 분산을 줄이기 위해 네트워크 맨 위에 위치합니다.
전처리 모듈은 5x5 kernel을 가진 2개의 residual block으로 이루어져 있습니다. 전처리 모듈에 더 큰 kernel을 사용함으로써 우리는 네트워크의 초기 단계에서 더 큰 receptive field가 다루어지는 동안 scale-specific한 부분을 얕게 유지 할 수 있습니다. multi-scale 모델의 끝에는 scale별로 upsampling 모듈이 병렬로 배치되어 multi-scale 재 구성을 처리합니다. upsampling module의 구조는 3.2.에서 설명한 upsampling 모듈과 유사합니다.
Final multi-scale model (MDSR)은 B = 80, F = 64입니다. single-scale baseline은 3개의 다른 scale을 가지고 각 scale은 1.5M parameter를 각각 가집니다. 총 4.5M parameter입니다.
multi-scale baseline은 3.2M개의 parameter만을 가집니다. 그럼에도 불구하고 single-scale model과 유사한 성능을 가집니다.
저자가 강조하고 싶었던 것은 multi-scale model은 depth 측면에서 확장이 가능하다는 것입니다.
MDSR은 multi-scale model base line에 비해 depth는 5배 가지고 가면서 parameter는 2.5배만 더 필요하다는 것입니다. EDSR에 비해서는 parameter수도 훨씬 적지만 비교할만한 성능을 보여준다는 것도 강조하였습니다.
※ memory와 processing time 측면에서는 유리할 것 같습니다.
4. Experiments
4.1. Datasets
DIV2K dataset (2K resolution), 800 training images, 100 validation images, and 100 test images.
Set5, Set14, B100, and Urban 100
4.2. Training Details
트레이닝을 위해 48x48 RGB patch들을 LR로부터 가져와서 학습을 진행하였습니다. (HR patches)
Random horizontal flips and 90 rotations.
ADAM optimizer , $\beta _{1} =0.9, \beta _{2} = 0.999, and \ \epsilon= 10^{-8}$
minibatch size = 16
learning rate initialize = $10^{-4}$, 2 x $10^{5}$ 마다 반절로 줄어듬
single-scale model (EDSR)을 위해 x2 model을 먼저 처음부터 training진행, 모델이 안정화 되면 다른 scale을 위해 이 것을 pre-trained network로 사용
multi-scale model (MDSR) 의 x2, x3, x4배 학습을 위해 minibatch를 각각 구성하여 랜덤하게 선택. 선택된 scale의 모듈만 enable되고 update 시킴 (scale-specific residual block과 upsampling module의 다른 scale은 disable, update 되지 않음)
L1 loss
Titan X로 EDSR은 8일, MDSR은 4일 학습 (EDSR이 MDSR에 비해 2배 더 오래걸림, 상품화에는 사용 불가능할듯)
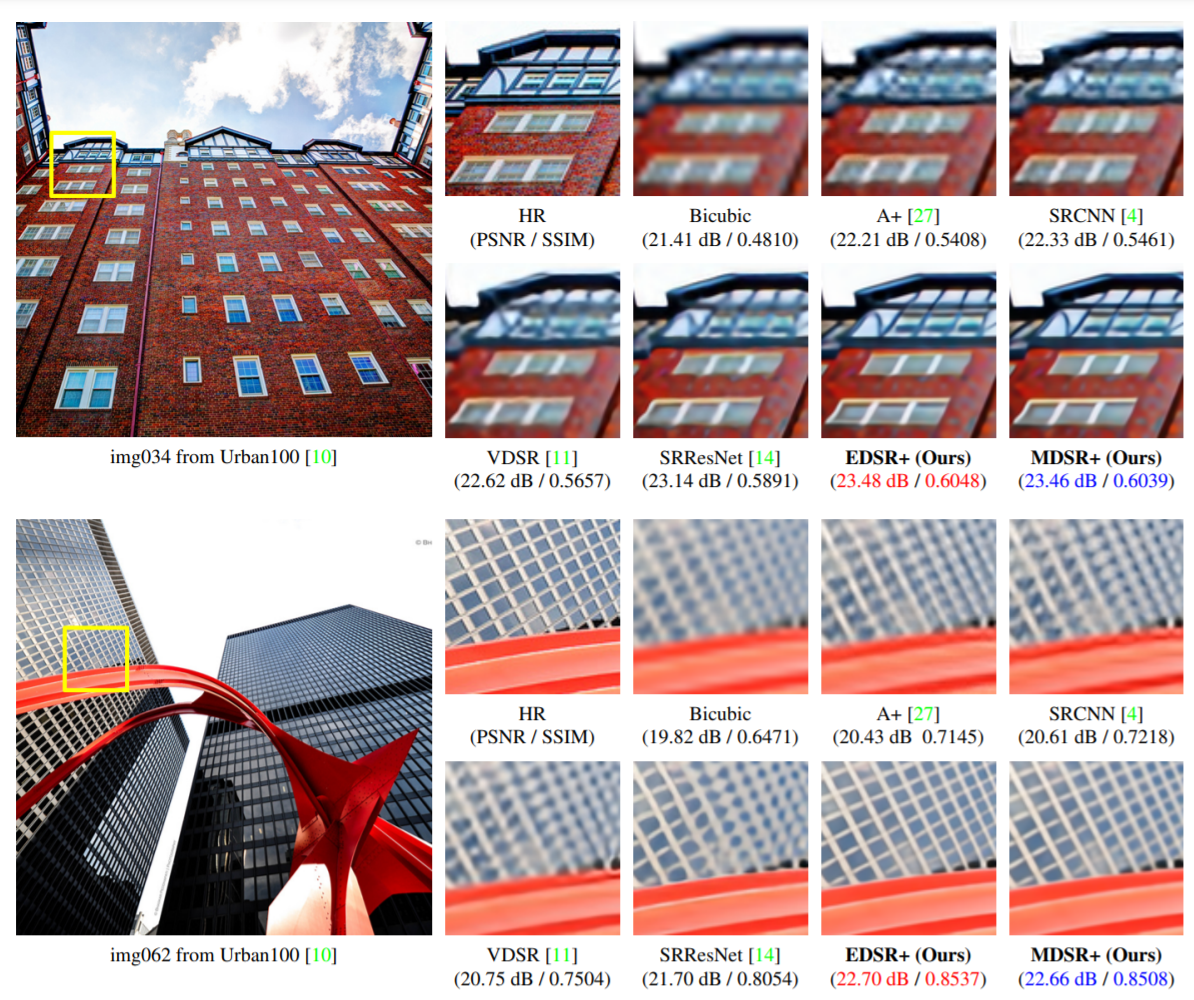
다른 이미지들에 비해 디테일이 개선되었고 blur함이 적어보이는 효과가 있었습니다. PSNR/SSIM도 개선됨을 확인하였습니다.
5. Conclusion
본 논문에서는 enhanced super-resolution algorithm을 제안하였습니다.
기존 ResNet 아키텍처에서 불필요한 모듈을 제거하여 모델을 소형화 하면서도 향상된 결과를 달성하였습니다. 또한 큰 모델을 안정적으로 훈련하기 위해 residual scaling이라는 기술을 사용하여 훈련을 하였습니다. 여기서 제안한 single-scale 모델은 state-of-the-art를 달성하였습니다.
모델 크기와 training 시간을 줄이기 위한 multi-scale super-resolution network도 개발을 하였고, scale-dependent 모듈 및 공유되는 main network를 통해 multi-scale 모델은 통합 프레임워크에서 다양한 scale을 효과적으로 처리할 수 있었습니다. 그러면서도 multi-scale모델은 single-scale 모델과 비교하여 상당히 간소화 되었고 성능도 조금은 떨어지지만 유사한 결과를 얻을 수 있었습니다.
[1] J. Kim, J. Kwon Lee, and K. M. Lee. Accurate image superresolution using very deep convolutional networks. In CVPR 2016.
[2] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunningham, ´ A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv:1609.04802, 2016.
[3] X. Mao, C. Shen, and Y.-B. Yang. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In NIPS 2016.
[4] H. Zhao, O. Gallo, I. Frosio, and J. Kautz. Loss functions for neural networks for image processing. arXiv:1511.08861, 2015.
'Artificial Intelligence > Paper' 카테고리의 다른 글
| Optical Flow Estimation using a Spatial Pyramid Network 리뷰 (SpyNet) (1) | 2023.05.25 |
|---|---|
| When Image Denoising Meets High-Level Vision Tasks: A Deep Learning Approach Review (0) | 2021.08.10 |
| Semantic Segmentation, DeepLab V3+ 분석 (0) | 2021.08.03 |



댓글