본 포스팅은 다음 과정을 정리 한 글입니다.
Custom and Distributed Training with TensorFlow
Custom and Distributed Training with TensorFlow
deeplearning.ai에서 제공합니다. In this course, you will: • Learn about Tensor objects, the fundamental building blocks of TensorFlow, understand the ... 무료로 등록하십시오.
www.coursera.org
지난 시간 리뷰
[Tensorflow 2][Keras][Custom and Distributed Training with TensorFlow] Week3 - Programming Assignment: Horse or Human?
본 포스팅은 다음 과정을 정리 한 글입니다. Custom and Distributed Training with TensorFlow https://www.coursera.org/learn/custom-distributed-training-with-tensorflow?specialization=tensorflow-ad..
mypark.tistory.com
이번 주에는 하나의 장치에서의 훈련을 넘어 여러 장치에서 훈련하는데 필요한 사항을 살펴보려고 합니다.
모델이 더 커지고 복잡해지면 하나의 CPU, GPU 또는 NPU에서 모델을 훈련시키는 것이 불가능 해질 수 도 있습니다.
따라서 이를 해결하기 위해 training을 분산하는 방법을 찾아야 할 수도 있습니다.
이러한 strategy(전략)는 사용 가능한 하드웨어가 무엇인가에 따라 다릅니다.
TensorFlow에서는 이를 지원하기 위해 다양한 전략들을 제공하고 있습니다.
머신 클러스터에 데이터를 배포할 수 있고 이러한 클러스터 각각에는 하나 이상의 장치가 있을 수 있습니다.
그에 따라 모델에 대한 대규모 training을 수행할 수 있습니다.
이를 일반적으로 Distribution strategy (배포 전략)라고 합니다. 이번 시간에는 Distribution strategy가 작동하는 방식에 대해 배우려고 합니다.

TensorFlow의 분산 교육은 데이터 병렬 처리를 중심으로 구축됩니다. 여러 장치에 동일한 모델을 복제하고 입력 데이터의 각각 다른 조각들을 실행시킵니다.
따라서 맨 위 행에서 전체 데이터 세트가 1, 2, 3, 4로 각각 다른 데이터 조각에 저장되어 있는 것을 볼 수 있습니다. 그 아래 행에는 별도의 머신이 있으며(여기에서는 4개) 각 머신에는 Training 할 동일한 모델의 복사본이 있습니다.

각 데이터 조각은 모델이 포함된 특정 시스템에 공급됩니다. (빨간색으로 표시된 부분 참고)
따라서 이러한 각 카테고리는 별도의 시스템에서 실행되는 별도의 프로세스로 간주되어야 합니다. 동일한 모델 아키텍처가 각각에 존재할 수 있습니다. 그러나 데이터가 다르기 때문에 각 모델의 가중치는 다르게 학습됩니다.
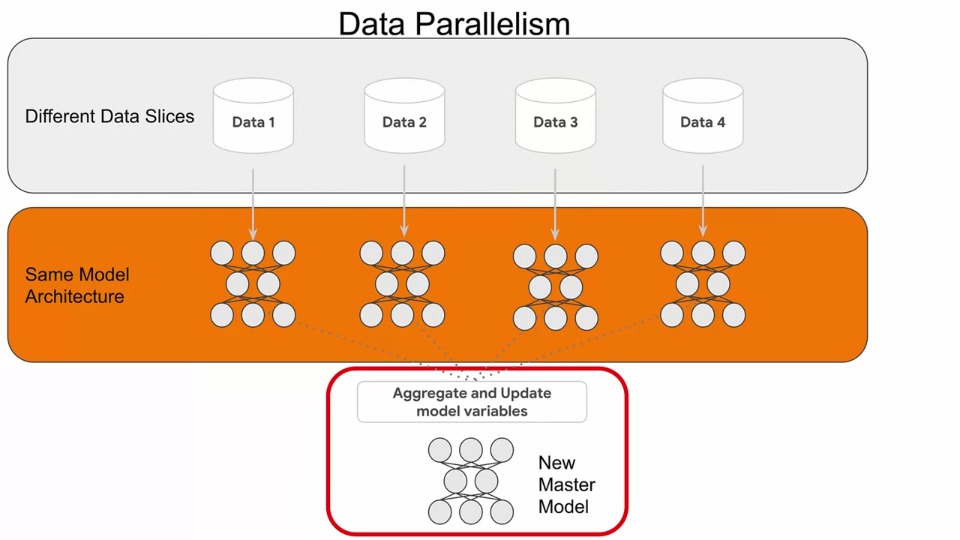
이 각각 학습된 가중치는 마지막에 새 마스터 모델로 합쳐지고 update가 되어야 합니다. 이러한 과정이 위의 그림에 설명되어 있습니다.

TensorFlow의 모든 분산 교육의 핵심은 tf.distribute.strategy 클래스 입니다. 이 클래스는 keras와 같은 TensorFlow의 High level API에 대한 다양한 배포 전략을 지원합니다. 이 클래스는 계속 살펴본 custom training loop와 동일한 유형입니다.
tf.distribute.strategy는 또한 TensorFlow2 code를 지원하도록 설계되었습니다. Eager 모드와 graph모드 코드 역시 TF function을 통해 생성됩니다.
그리고 이러한 모델을 Training 하는 것과 함께 이러한 API가 하드웨어 가속기의 다양한 구성에서 분산 방식으로 모델 평가 및 예측을 수행할 수도 있습니다.
사용 용이성은 이러한 API 설계하는 데 주요 요소가 되었습니다. 따라서 분산 Training을 가능하게 하기 위해 모델을 조정하는데 필요한 최소한의 추가 코드만 필요합니다.
Keras의 API에서 사용하는 변수, 레이어, 모델, 옵티마이저, 메트릭, 요약 및 체크포인트를 포함할 수도 있습니다. 이 모든 기존 기능이 활용 가능합니다. 또한 다양한 전략 간을 쉽게 전환하여 자신에게 가장 적합한 전략을 찾을 수 있습니다.

Distribution Strategy를 이야기할 때 몇 가지 새로운 개념과 용어가 있습니다.
지금은 익숙하지 않을 텐데 하나씩 살펴봅시다.

우리는 기계 학습 모델을 훈련시키는 모든 종류의 기계를 지칭하기 위해 Device라는 용어를 사용할 것입니다.
이것은 CPU일 수도 있고 GPU나 TPU처럼 Accelerator (가속기) 일 수도 있습니다.
한 대의 컴퓨터에 여러 Device가 있을 수 있습니다.
예를 들어 머신에는 하나의 CPU와 두 개의 GPU가 있을 수 있습니다. pre-processing 및 model training에 사용할 수 있는 3개의 device가 있는 것입니다.
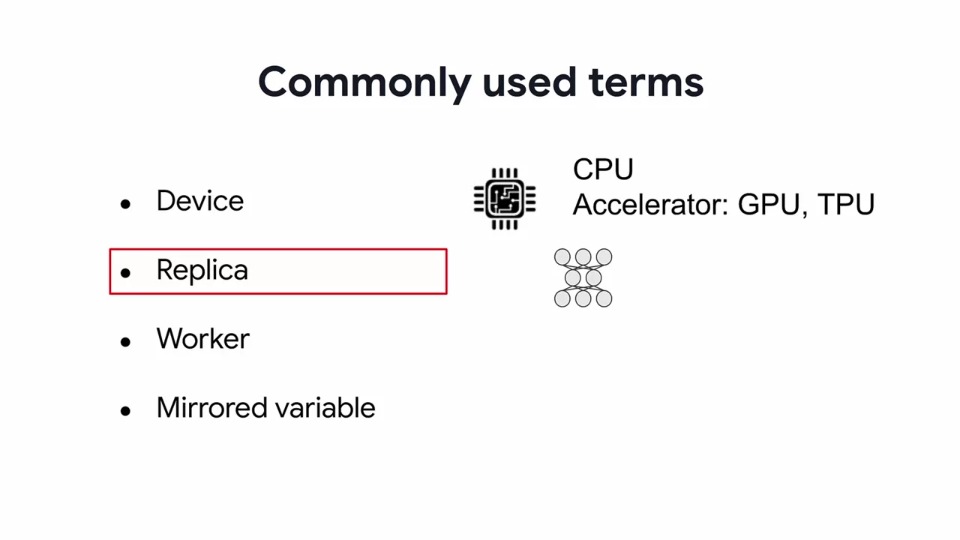
Training 동안 모델 variable의 복사본이 여러 device에 배치됩니다. 이 복사본을 종종 Replica(복제본)라고 합니다.

Worker (작업자)는 해당 Device에 있는 Replica 교육 전용으로 Device에서 실행되는 소프트웨어이며, Replica의 일부 변수는 다른 Replica와 독립적으로 훈련됩니다.

모든 장치에서 동기화하려는 몇 가지 변수가 있습니다. 모든 Device에서 동기화를 유지하려는 모델 내의 변수를 Mirrored Variable이라고 합니다.

병렬 처리가 발생할 수 있는 여러 위치와 이를 위한 전략을 어떻게 설계해야 하는지에 대해 생각하는 것은 매우 중요합니다. 병렬 처리가 발생하는 한 영역은 하드웨어 플랫폼입니다.
여기 CPU 및 하나 이상의 GPU와 같은 여러 Device가 있는 단일 machine이 있는 하드웨어 플랫폼 있습니다. 하드웨어 플랫폼의 또 다른 가능한 설정은 네트워크에 여러 machine이 있는 것입니다.
이러한 각 machine에는 서로 다른 수의 device가 있을 수 있으며 일부는 아예 없을 수도 있습니다.
병렬 처리가 문제가 될 수 있는 두 번째 영역은 Training에 접근하는 방법입니다.
데이터 병렬 처리를 통한 Training 방법에는 두 가지 유형이 있습니다.
Synchronous (동기화) / Asynchronous (비동기) Training이 있습니다.
- Synchronous Training에서 모든 worker는 서로 동기화되어 서로 다른 입력 데이터 조각에 대해 훈련합니다. 그들은 all-reduce 알고리즘을 사용하여 각 단계에서 계산된 gradient를 집계합니다. 이 것이 이 과정에서 주로 사용하게 될 Training 유형입니다.
- Asynchronous Training에서는 모든 worker는 입력 데이터에 대해 독립적으로 훈련하고 해당 변수를 비동기식으로 업데이트합니다. Parameter server architecture라는 것을 통해 분산 모델을 동기화합니다.

TensorFlow는 이전 슬라이드의 시나리오를 사용하여 학습을 하는데 도움이 되는 다양한 전략을 지원합니다.
위에 나열되어 있는 것이 지원하는 전략들입니다.
MirroredStrategy는 일반적으로 하나의 machine이 있지만 여러 GPU를 지원하는 경우 Distributed training을 할 때 사용하는 전략입니다.

여기서 아이디어는 각 GPU에 모델 replica를 생성한 다음 변수를 미러링 한다는 것입니다. 각 훈련 에포크 후에 학습된 매개변수는 각 장치에서 all-reduce를 사용하여 합쳐지게 됩니다.

TPUStrategy은 GPU 대신 TPU 코어를 사용한다는 점을 제외하면 Mirrored Strategy와 매우 유사합니다. 사용 가능한 NPU가 있는 경우 이 전략을 대신 사용할 수 있습니다.

MultiWorkerMirroredStrategy는 네트워크에 여러 machine이 있는 시나리오에 대해 미러링 된 전략을 기반으로 합니다. 이들은 차례로 여러 개의 GPU를 가질 수 있습니다. 이를 관리하기 위해 각 GPU device 대신 각 worker에 복제 및 미러링 한 다음 하드웨어 설정을 기반으로 하는 All-reduce 알고리즘을 사용합니다. 이것은 네트워크 설정에 맞게 사용자 정의된 매우 구체적인 전략입니다.

CentralStorageStrategy는 일반적으로 하나의 system 전략입니다. 그러나 machine이 여러 GPU가 있는 경우 여러 GPU 간에 변수를 미러링 하는 대신 CPU에 저장하고 처리합니다. GPU가 하나만 있는 경우 미러링 된 변수가 필요하지 않으므로 GPU가 사용됩니다.

Parameter server는 독립적인 데이터 저장 장치와 같은 machine입니다. 기계 학습 모델의 weights, biases 또는 필터와 같은 parameter 또는 변수의 데이터베이스가 중앙 서버에 저장됩니다.
parameterServerStrategy를 사용하면 네트워크의 일부 machine은 training을 수행하는 worker가 되고 다른 machine은 parameter server가 됩니다. 이렇게 하면 variables가 모두 중앙 parameter server에 저장되기 때문에 variables를 복제하거나 미러링 할 필요가 없습니다.

마지막으로 DefaultStrategy와 OneDeviceStratgey에 대해 알아보겠습니다.
하나의 machine에서 코드를 프로토타이핑하는데 주로 사용되며 나중에 분산 플랫폼에서 사용할 수 있는 전략입니다.
DefaultStrategy는 지원되는 벡엔드가 없어도 distributed strategy를 생성할 수 있는 효과적인 방법입니다. 여러 개의 GPU나 네트워크, machine 등이 필요하지 않습니다.
OneDeviceStrategy는 모든 훈련 매개변수, 모든 데이터 및 모든 앱을 하나의 device에 명시적으로 배치합니다. 모든 입력은 해당 장치로 유입됩니다.
다음 시간부터 이러한 전략들에 대해 자세히 살펴보겠습니다.
감사합니다.



댓글