Custom and Distributed Training with TensorFlow
Custom and Distributed Training with TensorFlow
deeplearning.ai에서 제공합니다. In this course, you will: • Learn about Tensor objects, the fundamental building blocks of TensorFlow, understand the ... 무료로 등록하십시오.
www.coursera.org
지난 시간 리뷰
[Tensorflow 2][Keras][Custom and Distributed Training with TensorFlow] Week2 - Custom Training Loops
[Tensorflow 2][Keras][Custom and Distributed Training with TensorFlow] Week2 - Custom Training Loops
본 포스팅은 다음 과정을 정리 한 글입니다. Custom and Distributed Training with TensorFlow https://www.coursera.org/learn/custom-distributed-training-with-tensorflow?specialization=tensorflow-ad..
mypark.tistory.com
지난 시간에는 X를 Y에 일치시키는 간단한 선형 회귀 예제 (y = mx + b)에 대해 Custom Training Loop를 만드는 방법을 살펴보았습니다.
이번 시간에는 더 큰 데이터 세트로 classification을 수행하는 방법에 대해 배우려고 합니다.
Fashion MNIST를 사용하여 custom training을 구현하는 방법을 살펴보겠습니다.

지난번에 사용한 합성 데이터 대신 custom training loop는 TensorFlow 데이터 세트를 사용하여 입력 파이프라인을 가져올 것입니다. 직접 작성하는 대신 훈련 루프 내에서 기존 손실 함수 및 optimizer를 사용할 것입니다.
이와 같은 분류기(Classifier)를 훈련할 때 테스트 세트를 사용하여 성능을 검증해야 하는데, 훈련 루프에서 이를 수행하는 방법에 대해서도 살펴볼 것입니다.
마지막으로 모델 트레이닝 중 metrics를 다루는 방법에 대해서도 살펴보겠습니다.

지난 시간에 배웠던 모델을 정의하고 훈련하는 5단계를 기억하시는지 모르겠습니다 ㅎㅎ
모델을 정의한 다음 훈련 데이터 파이프라인을 준비합니다. 사용할 optimizer와 loss를 선택한 다음 훈련하는 동안 optimizer를 사용하여 손실을 최소화합니다. 마지막으로 모델을 테스트합니다.
이제 새로운 예제를 통해 단계별로 살펴보겠습니다.

이번에는 weight와 bias만 있었던 이전 예제보다 조금 더 정교한 모델입니다.
Functional API를 사용하여 784개의 입력을 받는 입력 레이어가 있는 심층 신경망을 정의합니다.
입력은 옷 이미지가 될 것이므로 입력 레이어의 이름을 옷으로 지정하겠습니다. 그런 다음 각각 64개의 뉴런으로 구성된 두 개의 Dense 레이어를 만듭니다.
모델은 각 의류 항목이 10개 범주 중 하나에 속하는지 여부를 예측하므로 10개의 뉴런이 있는 출력 레이어를 생성하는데 이는 softmax에 의해 활성화됩니다.
모델은 tf.keras.model을 사용하여 instance화 되고 입력 및 출력 레이어를 parameter로 넣어줍니다.
Dense 계층의 뉴런에는 weight와 bias가 있다는 거 기억하시나요?!
이 138개의 뉴런 각각은 훈련 가능한 매개변수로 이 모델을 좀 더 정교하게 만듭니다.

다음은 훈련 파이프라인을 준비하는 것입니다.
TensorFlow 데이터 세트(TFDS)를 사용하여 훈련 데이터를 가져옵니다. 우리는 이 데이터를 정규화(normalize) 해야 하는데 pixel값은 0~255 사이입니다. 이 것을 0~1 사이의 범위를 갖도록 정규화해줍니다.
마지막으로 데이터도 훈련 세트(Training set)와 테스트 세트(Test set)로 분할합니다.

다음은 데이터 파이프라인을 준비하는 코드입니다.
먼저 tfds.load를 호출하여 Fashion MNIST에서 training data를 얻는데 split = "train"으로 설정합니다.
마찬가지로 tfds.load를 다시 호출하여 "fashion_mnist"와 split = "test"을 설정하여 test_data를 얻습니다.
그런 다음 모델에 input으로 쓸 수 있도록 데이터 형식을 설정하는 함수를 구현합니다.
먼저 data안에 "image"를 불러와 저장하고 1차원 배열로 병합을 합니다. 그런 다음 tf.cast를 사용하여 픽셀을 정수에서 부동 소수점 (float32)로 변환하여 255로 나누어 줍니다. 그러면 0~1까지의 범위로 image가 정해집니다.
그런 다음 format이 변경된 이미지와 관련 레이블을 모두 튜플로 반환합니다.
train_data.map() 함수를 사용하여 훈련 데이터의 각 이미지에 format_image 함수를 적용합니다. 이 map함수는 단지 표준 TFDS 매핑 기능입니다.
마찬가지로 test_data도 .map을 호출하여 데이터를 가공합니다.
일반적으로 데이터를 섞을 때 모든 값이 메모리에 로드되고 모든 것이 한 번에 섞입니다. 그러나 컴퓨터 메모리에 동시에 모두 담기에는 너무 큰 훈련 데이터로 작업을 할 때도 있습니다. 큰 데이터 세트로 작업하려면 훈련 데이터 세트에서 처음 1024개 예제의 버퍼사이즈로 시작하여 메모리에 보관한 다음 해당 버퍼에서 무작위로 샘플링할 수 있습니다. 이 경우 배치 크기가 64인 .batch를 호출하므로 버퍼에 있는 1024개의 데이터 셋에서 한번에 하나씩 64개의 임의 값을 샘플링합니다.
배치에 예제가 추가될 때마다 데이터 세트에서 다른 데이터 셋들을 가져와 버퍼에 넣습니다.
셔플은 1024개 데이터 셋의 버퍼로 남아 있습니다. 이 버퍼는 계속 유지됩니다.
train_data 세트를 반복할 때마다 해당 버퍼 1024에서 무작위로 샘플링된 64개의 데이터 배치를 얻게 됩니다.
다음으로 손실 함수(loss function)와 optimizer를 선택할 수 있습니다.

손실 함수의 경우 의류의 10가지 카테고리를 분류할 때 카테고리 예측을 처리하는 함수가 필요합니다. 희소 범주형 교차 엔트로피 (Sparse categorical cross entropy)를 여기서는 사용할 수 있습니다.
카테고리 레이블들이 정수이고 아직 one-hot 인코딩 되어있지 않은 경우 희소 범주형 교차 엔트로피를 사용합니다.
희소 버전은 일반 범주형 교차 엔트로피 보다 메모리와 계산 효율이 조금 더 높습니다.
여기에서 Optimizer는 표준 Adam을 선택하였습니다.

다음 단계는 Custom Training Loop를 정의하고 사용하는 것입니다.
이전과 마찬가지로 각 epoch에 대해 batch를 반복하고 예측을 얻은 다음 훈련 가능한 각 변수에 대한 손실 함수의 기울기를 계산합니다. 그런 다음 optimization 알고리즘을 사용하여 훈련 가능한 변수를 업데이트한 다음 평가하고 반복합니다.

우리는 이전 시간에 본 것과 유사한 이 Flow chart대로 학습을 진행할 것입니다.
모델을 초기화한 다음 각 epoch에 대해 예측을 계산하고, 손실을 측정하고, Gradient를 얻고, 손실을 최소화하는 방향으로 값을 변경시킵니다. 모든 epoch이 끝나면 모델 학습이 끝납니다.
그러나 이 경우에는 비 훈련 데이터에 대한 모델의 정확도에 대해 보고할 수 있도록 validation 검사 루프도 수행할 것입니다. 이것이 훈련 루프에 어떤 영향을 미치는지 살펴보겠습니다.
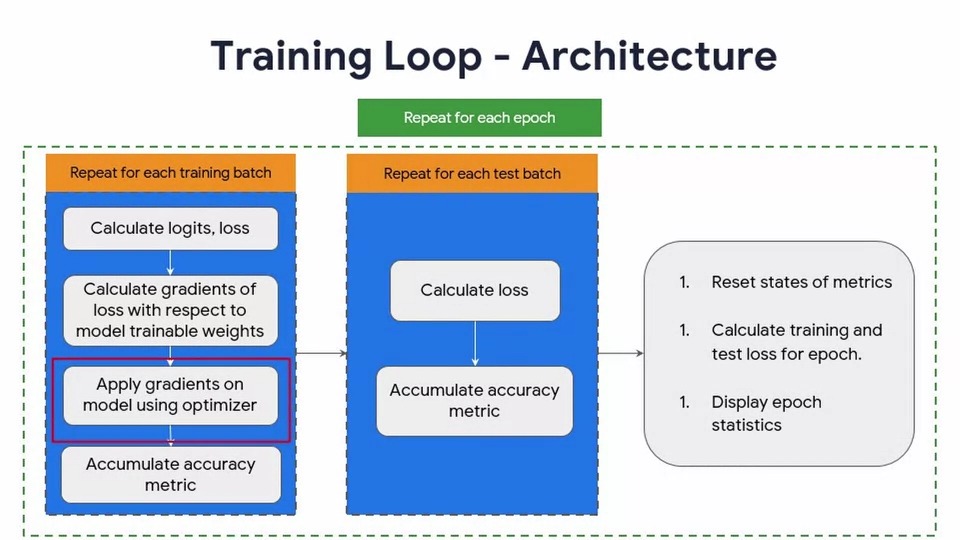
n개의 Epoch에 걸쳐 훈련을 수행하는 for 루프는 여기에 표시된 것처럼 더 세분화할 수 있습니다. 조금 더 깊이 들어가 보겠습니다.
훈련 데이터의 각 배치에 대해 먼저 logits을 계산하고, 현재 입력 배치에 대한 모델의 출력과 손실 함수에 의해 계산된 손실 값을 계산합니다.
여기서 logit이란
딥러닝에서 로짓
[0,1][0,1] 범위인 확률을 [−∞,∞][−∞,∞] 범위로 넓히는 로짓의 특성 때문에, 딥러닝에서는 확률화 되지 않은 날 예측 결과를 로짓이라고 부른다. 멀티 클래스 분류 문제에서 보통 softmax 함수의 입력으로 사용된다.
https://haje01.github.io/2019/11/19/logit.html
그런 다음 각 모델의 학습 가능한 변수에 대한 손실 기울기(gradients of loss)를 계산합니다.
그런 다음 이러한 gradient와 optimizer를 사용하여 모델의 학습 가능한 변수를 업데이트하고 마지막으로 정확도 metric을 계산합니다.
이것은 단순히 얼마나 많은 예측이 정확했는지에 대한 몫을 모델이 시도한 예측의 수로 나눈 값을 제공합니다.
테스트 세트의 각 배치에서 손실 함수를 사용하여 손실을 계산하고 테스트 세트에 대한 예측이 얼마나 정확했는지 계산하고 예측된 모델의 테스트 예제 수로 나누어 정확도 metric을 계산합니다. 그런 다음 훈련 세트의 각 배치에 대한 손실의 평균을 취하여 전체 epoch에 대한 훈련 손실을 계산할 수 있습니다. 우리는 epoch에 대한 전체 테스트 손실을 얻기 위해 테스트 손실에 대해 동일한 작업을 수행합니다. 마지막으로 각 epoch에 대한 훈련 통계를 출력/표시합니다.
그 후, 다음 epoch에 대해 최신 상태가 되도록 metric 상태를 재 설정할 수 있습니다.

이제 코드에서 살펴보겠습니다. 다음은 20 Epoch 훈련 루프에 대한 코드입니다.
먼저 모델을 인스턴스화 합니다. (model = base_model()) 이 것은 앞에 1번 Define network에서 이전에 정의된 model입니다.
그런 다음 루프를 20 Epoch 동안 실행하도록 설정하고 곧 보게 될 train_data_for_one_epoch() 함수에서 훈련이 수행됩니다. 이것은 현재 epoch에 대한 훈련 데이터의 losses를 반환합니다. (logits, loss_value)
검증 세트의 유효성을 검사하기 위해 perform_validation() 함수를 수행합니다. 이 기능도 곧 보게 될 것입니다. 이것은 현재 epoch에 대한 losses를 반환합니다. 우리는 이 값을 사용하여 훈련 세트와 검증 세트 모두에서 손실의 평균을 계산할 수 있습니다.

이제 train_data_for_one_epoch 함수를 살펴봅시다.
우리는 이 네트워크를 훈련할 때 배치 데이터를 사용하고 있으므로 각 배치에 대한 손실을 추가할 losses라는 list를 생성합니다. 데이터가 일괄 처리되므로 여러 단계를 거쳐야 합니다. for 루프의 각 반복에서 train 데이터 세트 반복자는 x_batch_train과 y_batch_train의 튜플인 64개의 예제 배치를 생성합니다.
enumerate를 사용하여 일괄 처리하고 있으며 각 루프에서 처리 중인 번호를 추적하기 위해 step을 사용합니다. 이를 출력하여 step의 상태를 확인할 수 있습니다.
각 단계에 대해 optimizer, 모델 및 x_batch_train, y_batch_train을 인자로 넣는 apply_gradient를 호출합니다. 이것은 우리에게 logits과 loss_value를 return 해 줄 것입니다. 이 함수는 우리가 곧 작성하게 될 사용자 정의 함수입니다. 그런 다음 이 배치에 대한 손실 값을 losses에 추가하고 루프가 완료되면 losses를 반환합니다. 이전에 이 함수를 호출하는 훈련 루프가 전체 손실을 얻기 위해 평균을 낸다는 것을 기억하세요.
배치 크기가 훈련 세트로 균등하게 분할되지 않으면 최종 배치가 다른 배치와 크기가 다르기 때문에 전체 평균이 왜곡이 될 수 있습니다. 약간만 왜곡이 될 수 도 있지만 왜곡이 된 것이니 문제가 될 수 있습니다.
예를 들어 MNIST에는 훈련 세트가 60,000개가 존재합니다. 이를 3개의 배치 25,000, 25,000, 10,000으로 나눌 경우에 전체 평균 손실이 10,000개 배치에 유리하게 편향되는 일이 생길 수 있습니다.

조금 전에 손실 값을 반환하는 appy_gradient 함수가 호출되는 것을 보았는데요. 이제 이 함수에 대해 살펴보겠습니다.
이제 GradientTape은 조금 친숙하지 않나요?
with tf.GradientTape() as tape: 로 시작해봅시다. 이를 통해 모델에서 훈련 가능한 모든 가중치에 대한 기울기를 계산할 수 있습니다.
그런 다음 x 값, 즉 훈련 데이터를 모델에 전달하고 logits을 얻습니다. 우리는 이것을 실제 값과 비교할 수 있습니다. 그러고 나서 logit을 y_pred에 y를 y_true에 넣고 손실 함수 (loss_object)를 호출하여 loss_value를 얻을 수 있습니다. 손실에 대해 미분하여 모델의 각 학습 가능한 가중치에 대한 기울기를 계산할 수 있습니다. 그런 다음 optimizer를 사용하여 계산된 gradient를 모델의 학습 가능한 가중치 업데이트에 사용합니다. (apply_gradients)
배치에 64개의 데이터가 있는 경우 gradients 변수에는 64개의 gradient 세트가 포함됩니다. 훈련 가능한 각 변수 집합에 하나씩. gradients이 업데이트할 64개의 gradients 배열과 64개의 훈련 가능한 변수를 정렬하기 위해 파이썬의 zip함수를 사용할 수 있습니다.

검증 계산은 간단합니다. 모든 손실을 저장할 배열을 만듭니다. (losses) 그런 다음 테스트 세트의 모든 배치를 반복합니다. 현재 배치에 대한 예측을 얻고 손실을 계산하고 그 결과를 손실 배열 (losses)에 추가하고 완료되면 호출자에게 모두 return 합니다.
perform_validation은 훈련 루프 내에서 호출되었으며 검사 손실은 전체 검사 손실에 대해 계산하기 위해 평균화를 하였습니다.

Metrics와 관련하여 TensorFlow의 Keras 라이브러리는 metrics에 접근할 수 있는 두 가지 방법을 제공합니다. 우리에게 반환을 제공하는 함수로 호출되거나 우리를 위해 metric을 처리하는 클래스를 인스턴스화 할 수 있습니다. 예를 들어 여기에 밑줄 기호가 함수로 정의된 mean_squared_error(...)를 볼 수 있습니다. 그리고 MeanSquaredError는 클래스로 정의된 경우입니다. mean_absolute_error(...) 역시 왼쪽에 있는 것은 함수이고 오른쪽에 있는 것은 클래스입니다.
전체 metric 세트는 위의 URL의 API문서 내 tensorflow.org에서 찾을 수 있습니다.

Metric을 사용할 때 고려해야 할 세 가지 중요한 방법이 있습니다.
metric.update_state()를 사용하여 metric의 상태를 업데이트할 수 있습니다. 그리고 이것은 일반적으로 각 배치 후에 수행됩니다.
metric.result()를 호출하여 metric 상태를 쿼리 할 수 있습니다. 그리고 이것은 현재 값을 제공하여 표시할 수 있습니다. 또는 원하는 값에 도달하면 훈련을 중지할 수도 있습니다.
일반적으로 각 epoch가 끝날 때 metric 상태를 재설정하므로 metric.reset_state()를 호출하여 다음 epoch에 reset 된 상태를 가질 수도 있습니다.

따라서 fashion mnist 경우 SparseCategoricalAccuracy() 함수를 사용하므로 해당 SparseCategoricaAccuracy metric을 사용할 수 있습니다. 여기서 클래스를 사용하고 훈련 및 검증을 위한 인스턴스를 생성할 수 있습니다. (Metrics를 클래스로 사용하는 예제)

훈련을 처리하기 위해 이전에 생성한 하나의 epoch 함수에 대한 훈련 데이터를 기억하는 경우 update_state를 호출하고 정답 레이블을 전달하여 훈련 정확도 metric의 상태를 간단히 업데이트할 수 있습니다. 이 경우 정답 레이블은 y_batch_train이고 현재 예측은 logits가 됩니다. metric 객체가 손실 및 정확도 계산 등과 같은 나머지 작업을 대신 수행하게 됩니다.

그런 다음 호출 루프에서 epoch가 완료되면 훈련 정확도 metric의 결과를 읽고 metric을 최종적으로 재설정하기 전에 모든 배치에서 수행한 작업을 확인할 수 있으므로 다음 epoch에 대한 준비가 됩니다.

유사하게, perform_validation에서도 검증 정확도 metric에서 update_state를 추가하여 y_val인 ground truth와 logits인 예측을 받아서 metric을 계산할 수 있습니다.
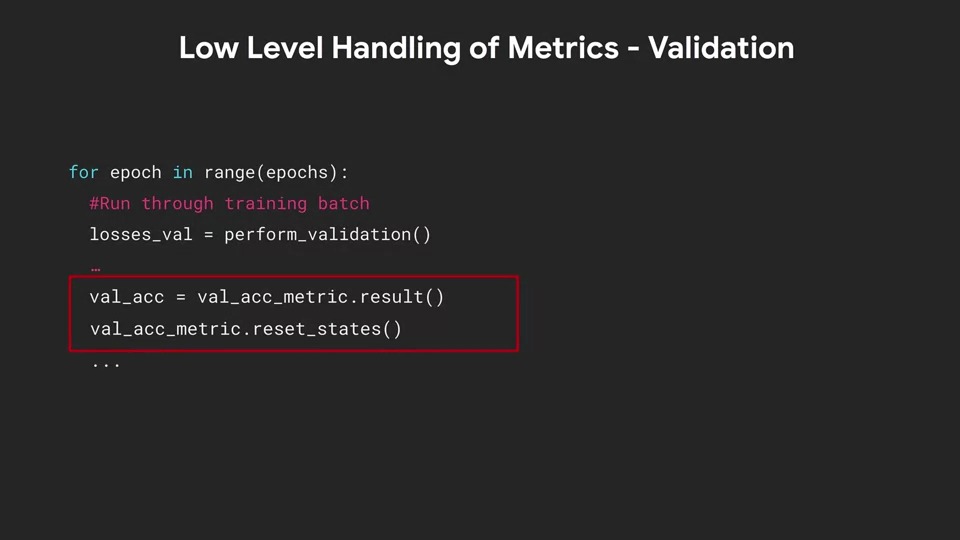
Main Training 루프에서 perform_validation을 수행한 후에 val_acc_metric.result()를 통해 metric의 결과를 가져올 수 있습니다. 그런 다음 metric을 reset 하면 다음 epoch으로 넘어갈 준비가 완료됩니다.

모델 검증은 epoch별로 training 진행 상황을 보여주고 loss와 accuracy를 계산하는 것입니다.
손실 함수에 대한 성능을 포함하여 metric 결과에 대한 그래프를 그릴 수 있습니다. 또한 테스트 데이터로 성능을 시각화할 수도 있습니다. 어떻게 사용할지는 사용자에게 달려 있습니다. 다양한 도구들을 사용해 보시기 바랍니다.
감사합니다.



댓글