반응형
본 포스팅은 Coursera – Generative Adversarial Networks 과정을 참고하였습니다.
안녕하세요~
오늘은 첫 번째 강의로 인사드립니다.
이번 시간에는 Generative model은 무엇인지?! Generative model의 종류는 무엇이 있는지 알아보려고 합니다.


Machine Learning의 분류 모델은 크게 두가지로 나누어지는데,
Discriminative models과 Generative models입니다.
먼저 Discriminative models에 대해 설명 드리겠습니다. 이는 Classification에 주로 이용됩니다.
여기서는 강아지와 고양이를 분류하는 것으로 예를 들었는데요!
강아지를 대표하는 특징들이 뭐가 있을까요? 혀를 내밀고 있다? 눈이 동그랗다? 뾰족한 귀? 등등 정도 생각이 나네요…
이러한 특징들을 X라고 하고 강아지, 고양이 등을 Y라고 하면,
혀를 내밀고 있을 때 강아지일 확률! => P(개 | 혀를 내밀고 있을 때) 를 구해서 반환하는 모델을 Discriminative model이라고 합니다.
이미지가 혀를 내밀고 있고, 뾰족한 귀를 가지고 있다면, 이 특징들을 가지고 이미지가 강아지인지 고양이인지를 판단하는 것입니다.
조건부 확률 P(Y|X)를 구하는 것이죠.
앗! 혀를 내밀고 있고, 뾰족한 귀를 가지고 있네? 그러면 아마 강이지일거야! 라고 판단을 하는 것이죠.
Discriminative model은 Y라는 레이블 정보가 있어야만 하기 때문에 지도학습의 카테고리로 들어갑니다. 이는 상당히 많은 학습데이터가 있으면 좋은 성능을 낼 수 있습니다.
다음으로 Generative model에 대해 설명 드리겠습니다.
Generative model은 어떻게 어떤 특정한 class를 현실적으로 만들지를 배우려고 노력합니다.
위의 예제에서는 강아지(class)를 생성하는 것을 예시로 들었는데요.
Generative model은 random 값을 input으로 취하는데, 강아지의 코를 대표하는 값을 random number 3이라고 하고 눈을 -5, 혀를 2.6이라고 해봅시다.
그럼 [-5 3 2.6] 이라는 벡터가 만들어 집니다.
이 값들은 그냥 제가 임의로 정한 값입니다.
이러한 random한 숫자 vector를 noise 라고 하고 이를 generative mode에 input(입력)으로 넣습니다.
Generative model은 가끔 class Y (강아지)를 input으로 받습니다.
이런 input들 (noise, class Y)를 가지고 사실적으로 보이는 강아지의 특징들(class X)을 가진 개 사진을 생성하는 것입니다. 예를 들면 혀를 내밀고 있거나, 뾰족한 귀를 가진 강아지 사진을 만드는 것이죠!
여기서 의문이 생길 것입니다... 도대체 왜 noise를 넣어야 되는거지??
noise없이 그냥, generative model에게 "헤이, 나를 위해 강아지를 만들어줘" 할 수 없는 것일 까요?
당연히 없이도 만들 수 있습니다. 하지만 noise가 없으면 동일한 강아지만 나오게 될 것이고, 이것은 의미가 없는 일이 될 수 있습니다.
noise가 커지면 동일한 강아지가 생성 되는 경우가 줄어듭니다. 결국 noise로 인해 다양한 강아지가 만들어 질 수 있다는 의미입니다.
일반적으로 Generative model은 X의 확률 분포를 포착하고 젖은 코, 혀를 내밀고 있는, 뾰족한 귀를 가지고 있어도 항상 Y가 강아지가 주어지는 것은 아닙니다.
노이즈가 추가되면 이 모델은 사실적이고 다양한 클래스 Y를 생성합니다.
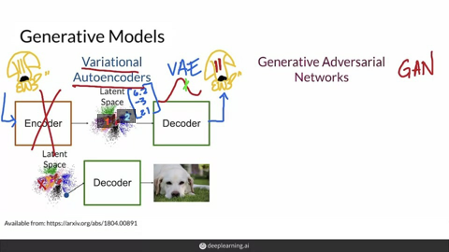
Generative model의 종류는 정말 다양하지만 여기서는 가장 유명한 것들만 소개해 드리겠습니다.
바로 Variational autoencoders, 짧게는 VAE, 그리고 Generative Adversarial Network, 짧게는 GAN입니다.
VAE는 두개의 모델로 이루어지는데, Encoder와 Decoder입니다. 이것들은 전형적인 neural networks입니다.
제 기억으로는 autoencoder 논문에서 사용하고 있는 구조인데 아래 블로그가 정리를 잘해 놔서 공유 드립니다~
https://excelsior-cjh.tistory.com/187
VAE의 학습 방법에 대해 알아보면, 먼저 VAE로 현실적인 강아지 사진들을 encoder로 넣어줍니다. encoder의 일은 이 불안정한 잠재 공간에서 그 이미지(강아지)를 표현하는 좋은 방법을 찾는 것입니다!!
위의 그림에 빨간색 글씨 1번으로 된 잠재공간에서 특정 포인트가 있다고 할 때, 이 점을 [6.2 -3 21] 이라고 해봅시다. 다음으로 VAE는 이 latent representation(잠재된 표현)이나 그것에 가까운 점을 취해서 decoder로 통과 시킵니다.
Decoder의 목표는 encoder가 보고 있던 저 강아지 그림을 그대로 복원해 내는 것입니다.
처음에 decoder는 완벽하게 encoder가 보고있던 강아지를 복원해내지 못할 것입니다. 예를 들면 위의 그림처럼 빨간 눈을 갖는 강아지로 만들어 낼 수도 있습니다.
Training이 완료되면, 우리는 encoder를 떼어내고, 아래 그림과 같은 잠재 공간의 임의의 지점들 중에 한 곳을 선택할 수 있게되고, decoder는 강아지의 현실적인 이미지를 생성하는 것을 배울 것입니다.

Variational part(변이 부분)는 실제로 이 전체 모델과 training 과정에 약간의 noise를 주입합니다.
Encoder가 이미지를 latent space(잠재 공간)의 단일 점으로 인코딩하는 대신, encoder는 실제로 이미지를 전체 distribution(분포)에 인코딩한 다음 해당 distirbution에 대한 점을 샘플링하여 그것을 decoder에 입력해서 실제 이미지를 생성합니다.
Noise를 약간 추가하면 이 distribution에서 서로 다른 점을 표본으로 추출할 수 있게 됩니다. 이러면 다양한 강아지 사진을 생성할 수 있는 것입니다!!
variational autoencoder의 정리는 아래 포스팅이 잘되어 있으니 궁금하신 분들은 방문해서 더 공부해보시면 좋겠습니다~
https://deepinsight.tistory.com/127

이번에는 GAN에 대해 알아보겠습니다.
GAN은 VAE와는 다른 방식으로 작동합니다.
GAN도 2가지 모델로 구성되어 있습니다. 바로 Generator와 Discriminator입니다.
Generator는 VAE의 decoder처럼 이미지를 생성하는 역할을 합니다.
Discriminator는 discriminative model이 들어가 있는 것이라고 보시면 됩니다.
Generator는 random noise를 input으로 취하는데 아래 그림의 예를 보면 [1.2 3 -5] vector를 generator의 input으로 집어 넣습니다.
처음에는 빨간 눈을 가진 개를 만들어 낼 수도 있습니다. 나중에는 동일한 강아지를 계속해서 만들어 낼 수 있습니다. (input이 고정되어 있으면)
Generator는 VAE에서 decoder와 어느정도 유사한 역할을 수행합니다. 다른 점은 가이드 해주는 인코더가 이번에는 없다는 것입니다. 대신에 GAN은 Discriminator라는 것이 있고, 이 것은 가짜와 진짜 이미지를 구별해내는 역할을 하게 됩니다. 어떠한 이미지가 들어 왔을 때 이것은 가짜다, 진짜다를 판별하는 것입니다.
Generator와 Discriminator는 서로 경쟁을 하게 되는데, 그래서 이 네트워크를 generative adversarial(대립의) 이라고 부르는 이유 입니다.
아래 그림 처럼 시간이 지남에 따라 근육이 자라는 것을 상상할 수 있습니다. 그들은 서로 경쟁하고 서로에게서 배웁니다. Generator는 Discriminator를 속일 수 있을 만큼 현실적인 강아지 사진을 만들어내려고 하고, Discriminator는 Generator가 만들어낸 가상의 강아지 사진을 가짜로 판별하기 위해 노력하면서 서로 강해지는 것입니다.
다시, Discriminator를 필요로 하지 않는 지점에 도달할 때까지 학습을 진행합니다.
그러면 Generator는 어떠한 random noise를 입력으로 받더라도 현실적인 강아지 사진을 만들어 낼 수 있게 됩니다.
예를 들면, [-5 6.2 8]의 random noise vector를 Generator의 입력으로 넣으면 귀여운 래브라도 리트리버가 생성 되게 되는 것입니다.

정리하면!!
Generative models 현실적인 이미지를 만들어내기 위해 학습을 합니다. 귀여운 강아지 사진이나 고양이 사진을 생성해 내기 위해 말입니다.
Generative model은 현실적인 사진 그림을 만들어 내기위해 노력하는 예술가 입니다.
Discriminative model은 다른 클래스들을 구별합니다.
예를들면 이 사진이 강아지인가 고양이 인가를 분별해 내는 것입니다. Discrimiative model은 generative model의 서브 구성요소가 될 수 있는데, GAN에서 봤던 생성된 강아지가 진짜 인지 아닌지를 분별해 내는Discriminator로도 사용 할 수 있습니다.
앞으로는 계속해서 이 GAN에 대해서 공부해 볼 것입니다.
감사합니다.
300x250
'Artificial Intelligence > GAN' 카테고리의 다른 글
| Week 1 : Intro to GANs - Intuition Behind GANs (0) | 2021.03.04 |
|---|---|
| Week 1 : Intro to GANs - Real Life GANs (0) | 2021.03.04 |


댓글