모든 기계 학습의 핵심은 매개 변수를 조정하여 특징들(Features)을 Label들과 일치시키는 데 사용되는 함수를 최적화 하는 것입니다.
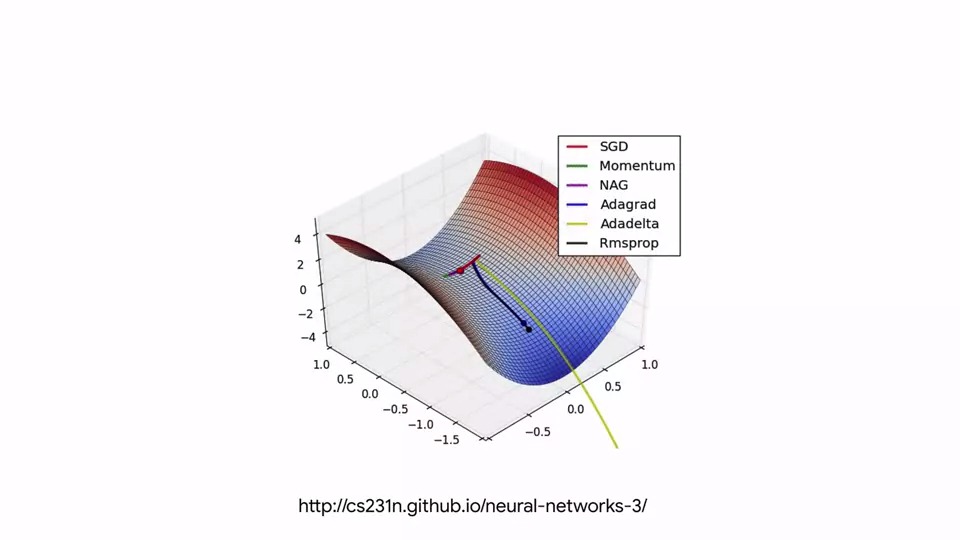
이러한 함수는 경사 하강 법(Gradient Descent)의 원리에 따라 작동하며 각 최적화 함수는 최적 값으로 향하기 까지 서로 다른 수렴 속도를 갖게 됩니다.
많은 연구자들이 다양한 시나리오에서 이러한 알고리즘을 실험하면서 발전되어 왔습니다.
TensorFlow에서 Optimizer는 TensorFlow API, Gradient Tape를 사용하여 구현됩니다.
이 API를 사용하면 모든 TensorFlow 작업의 기울기를 계산하고 추적 할 수 있습니다.
맞춤형 교육에 들어가면서 학습의 기울기(Gradient)가 작동하는 방식을 이해하는 것이 좋습니다. Gradient Tape의 개요도 살펴봅시다.
매우 간단한 예부터 시작하겠습니다. 이 경우, 우리는 x와 y의 집합을 가지고 있으며 x를 y와 동일하거나 비슷하게 만들고자 합니다.
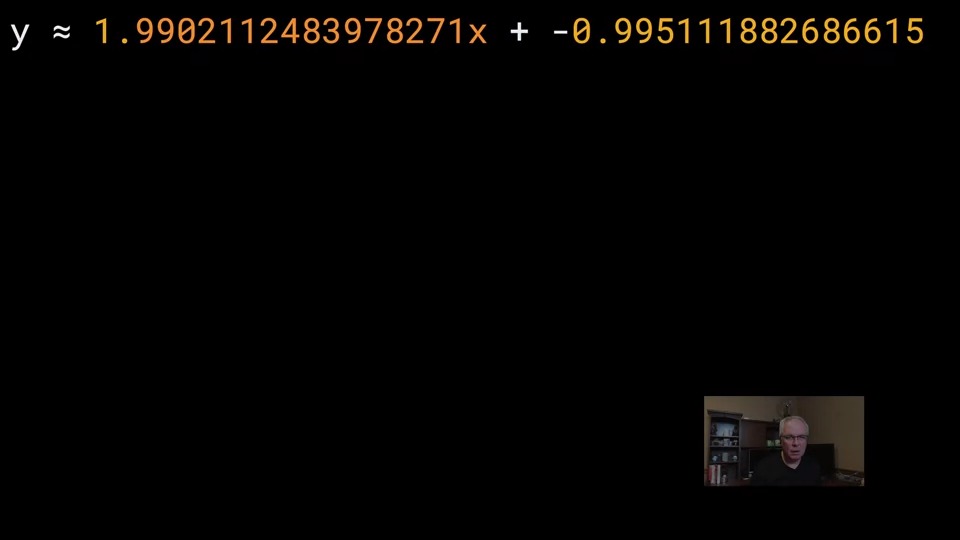
아래 예제는 y = 2x-1의 방정식을 사용하여 y 값을 생성해냈습니다.
두 개의 매개 변수 w와 b를 생성하고 모델이 w가 2와 같거나 2에 가까운 값을 가지는지, b가 1 또는 1에 가까운 것을 가지는지 학습할 수 있는지 확인합니다.
매개 변수는 학습 가능으로 설정되어 참이되므로 Gradient Tape가 w 및 b 텐서를 주시하고 모델을 최적화 할 때 이 것들을 미분 할 수 있습니다.

일반적인 기계 학습 방법을 살펴봅시다.
첫 번째 추측으로 w와 b를 무작위로 초기화합니다. 그런 다음 그 추측이 얼마나 정확한지를 계산한 다음 최적화 기법을 사용하여 경사 하강법을 통해 loss를 줄이게 됩니다.
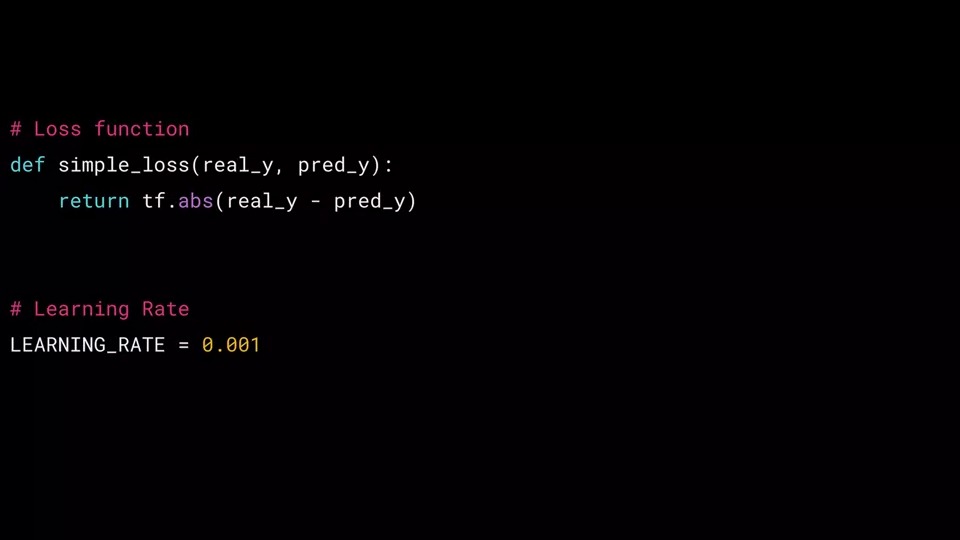
이 경우 real_y 값과 pred_y 값의 차이를 매우 간단한 손실 함수로 정의합니다. (차이에 절대값을 취함, simple_loss)
또한 Optimizer에 영향을 미치는 학습률(Learning Rate)이라는 매개 변수를 초기화 해야 하며 잠시 후에 살펴보겠습니다.
이제 훈련을 해봅시다.
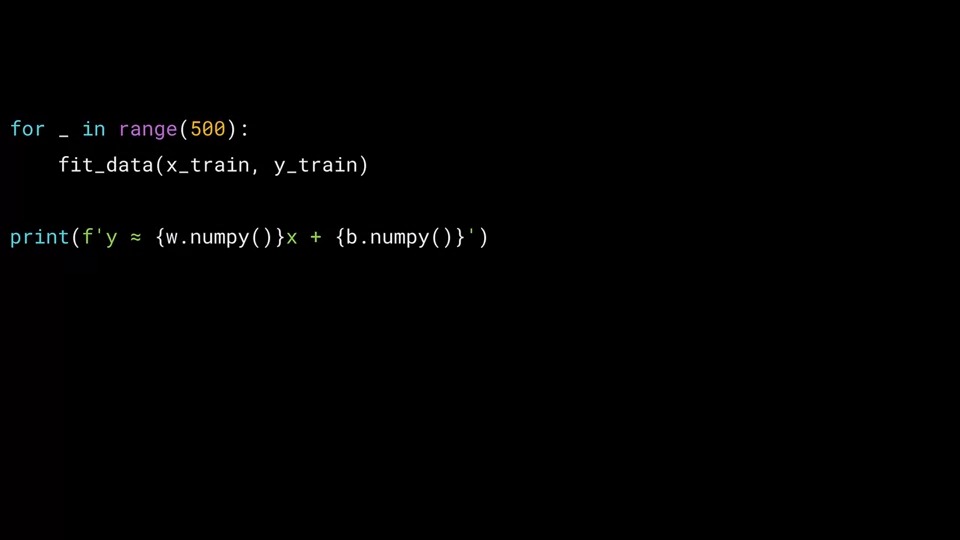
우리는 fit_data를 500번 호출을 할 것입니다.
500번을 호출 한 이후에 w와 b의 값을 출력할 것입니다.
for 루프에서 500번 호출을 하면서 x_train을 y_train 값에 근접하게 학습 하게 될 것입니다.
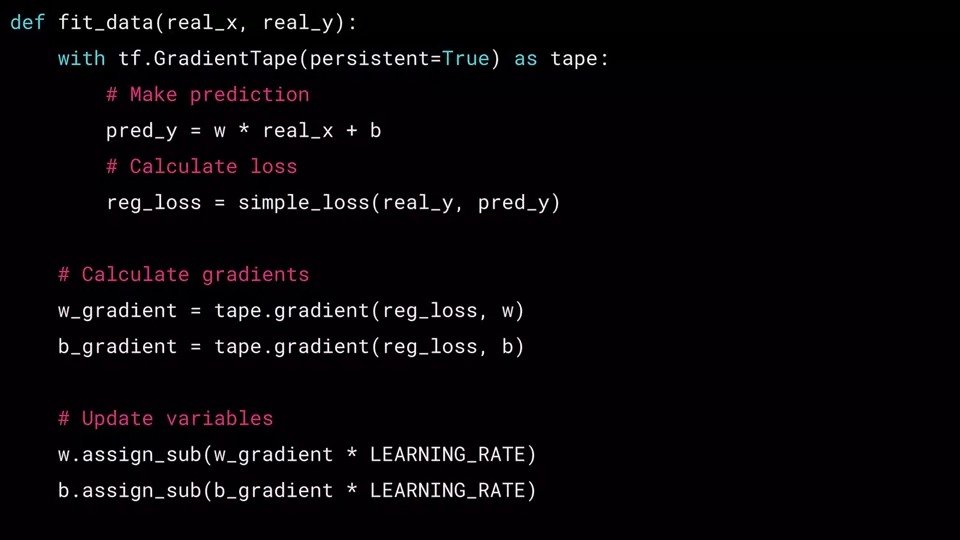
tf.GradientTape를 사용하려면 키워드 "with" 로 시작합니다. 그러면 아래의 일부 코드들을 들여쓰기를 하여 with에 속하는 코드임을 표시합니다. (#Make prediction, #Calculate loss 부분)
tf.GradientTape를 tape로 사용하여 변수 tape는 이제 GradientTape 유형의 객체이며 나중에 Gradient를 계산하는데 사용할 수 있습니다.
나중에 Gradient tapes 함수의 매개 변수 persistent=True에 대한 설명과 무엇을 하는 것인지에 대해 설명을 드릴 것입니다. 지금은 이 부분에 대해 모르셔도 상관이 없습니다.
GradientTape의 루프가 있는 내부에서는 일반적으로 두 가지 작업을 수행합니다.
먼저 예측을 계산합니다.
이 경우 현재 w와 b를 기반으로 pred_y를 계산합니다.
그런 다음 손실을 계산합니다.
여기서 reg_loss는 함수 simple_loss를 호출하여 반환 값을 저장하는 것을 볼 수 있습니다.
이 함수는 실수 y를 예측 된 y와 비교를 합니다.
w와 b에 대한 기울기를 얻기 위해 손실 값과의 미분 값을 구합니다.
tape.gradient 메서드는 이러한 미분 값을 구하는 기능을 제공합니다.
with-block 외부에서도 with-block 내부에 선언된 tape변수를 계속 사용할 수 있습니다.
w기울기의 경우 가중치 w에 대한 손실(reg_loss)의 미분을 얻고 싶습니다.
그러면 tape.gradient를 호출 할 때 다음과 같이 loss와 변수 w를 전달하면 => tape.gradient(reg_loss, w) 미분 값을 얻을 수 있습니다.
마찬가지로 b 기울기 역시 tape.gradient(reg_loss, b)로 호출을 해서 미분 값을 얻을 수 있습니다.
이 기울기의 음수는 w 및 b에 대한 최적 값의 방향을 가리 킵니다.
매우 기본적인 optimizer의 예를 보여주고 있습니다.
그런 다음 w 및 b 텐서의 경우 assign_sub를 호출하여 해당 값을 조정하기 위해 학습률과 gradient값을 곱하여 업데이트 할 수 있습니다.
역전파에 대한 수학이 생각이 나실지는 모르겠지만, 여기서 우리는 기중치 w를 w에 대한 손실의 gradient값을 뺀 값으로 업데이트 할 것입니다. 여기서 gradient는 학습률에 의해 크기가 조절됩니다.
assign_sub는 빼기를 수행하고 결과를 다시 w에 할당합니다.
이제 루프 500번이 다돌았으니
w와 b의 출력 결과를 봅시다.
학습 이후에 w는 2에 가까운 값을 b는 -1에 가까운 값을 얻게 된 것을 볼 수 있습니다.
더 자세히 알아보고 싶으신 분은 아래 글을 참고하시기 바랍니다.
https://cs231n.github.io/neural-networks-3/
CS231n Convolutional Neural Networks for Visual Recognition
Table of Contents: Learning In the previous sections we’ve discussed the static parts of a Neural Networks: how we can set up the network connectivity, the data, and the loss function. This section is devoted to the dynamics, or in other words, the proce
cs231n.github.io



댓글