반응형
본 포스팅은 다음 과정을 정리 한 글입니다.
Custom Models, Layers, and Loss Functions with TensorFlow
www.coursera.org/specializations/tensorflow-advanced-techniques
지난 시간 리뷰
2021.03.20 - [Artificial Intelligence/Keras] - [Tensorflow 2][Keras] Week 2 - Custom loss hyperparameters and classes
[Tensorflow 2][Keras] Week 2 - Custom loss hyperparameters and classes
본 포스팅은 다음 과정을 정리 한 글입니다. Custom Models, Layers, and Loss Functions with TensorFlow www.coursera.org/specializations/tensorflow-advanced-techniques 지난 시간 리뷰 2021.03.18 - [Artif..
mypark.tistory.com
지난 시간에는 Huber Loss를 구현해 보았습니다. 이번 시간에는 contrastive loss에 대해 구현해 보도록 하겠습니다.
아래 그림은 이미지 유사성을 체크하기 위한 Siamese Network였습니다. 이 네트워크는 두 개의 동일한 네트워크 구조를 가지고 있고 output vector룰 두 개 뱉어내서 Euclidean distance를 구하고 한 개의 output, 유사도를 계산해 내었습니다.
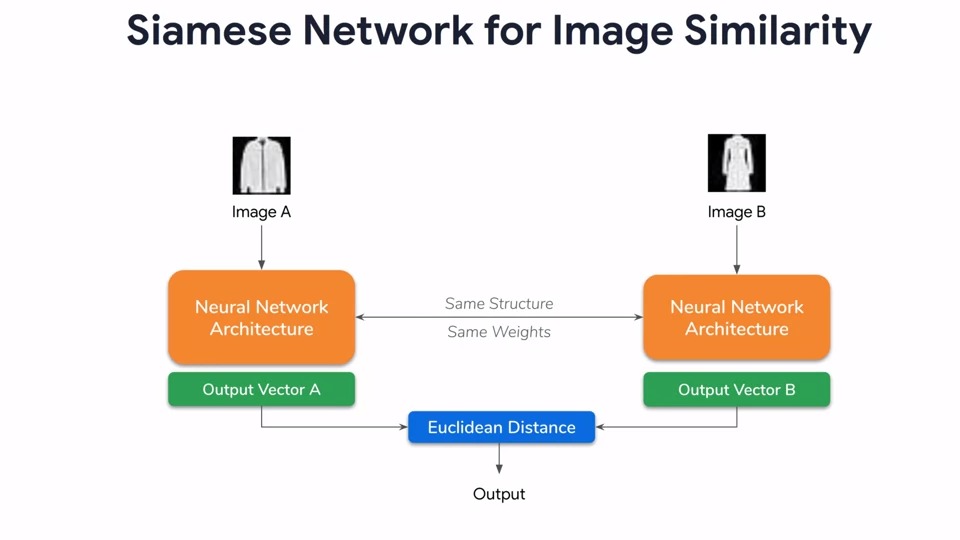
이 과정에서 발생하는 loss를 계산하기 위해서는 keras의 api에는 포함되지 않은 새로운 유형의 손실 함수가 필요합니다. 우리는 이것을 contrastive loss라고 불렀는데 왜냐하면 우리는 이미지들을 서로 대조하고 싶었기 때문입니다.
아이디어는, 만약 두 이미지들이 비슷하면 매우 유사한 feature vector를 생성하고자 합니다. 반면에 두 이미지가 다르다면 feature vector도 달라야만 합니다.
"Dimensionality Reduction by Learning an Invariant Mapping" 논문이 우리가 만들고자 하는 loss의 base가 됩니다.

Contrastive Loss의 공식은 아래와 같습니다.
여기에 많은 것들이 있는데요 하나씩 차례로 살펴봅시다.
여기서 Y는 이미지 유사성에 대한 세부 정보의 텐서입니다. 이미지가 비슷하면 1이고 그렇지 않으면 0입니다.
D는 이미지 쌍 사이의 유클리드 거리의 텐서입니다.
margin은 유사하거나 다른 것으로 간주하기 위해, 이들 사이의 최소 거리를 적용하는 데 사용할 수 있는 상수 값입니다.

그럼 Y가 1일 때 어떤 일이 일어나는지 보시죠~
Y가 1이 되면 뒤의 max값은 의미가 없어지고 D^2만 남게 됩니다.
그래서 우리는 비슷한 이미지가 들어오면, 높은 값을 가지게 되는 것입니다.

반대로 Y가 0이면 D^2 값은 의미가 없어지게 되고 margin에서 D를 뺀 값 또는 0 사이의 최댓값이 되고, 이 값은 D^2 보다 훨씬 작은 값이 될 것입니다.

이 Loss function에서 Y와 (1-Y)는 일종의 가중치라고 생각하시면 되는데요.
만약 Y가 1에 가까우면 D^2항에 더 많은 가중치가 부여되는 것이고 max(margin - D, 0)^2항에는 더 적은 가중치가 부여됩니다.
반대로 Y가 0에 가까우면 D^2항에는 더 적은 가중치가 부여되고 max(margin - D, 0)^2항에는 더 많은 가중치가 부여됩니다.
그럼 Tensorflow에서 사용하는 값으로 해당 식을 변경해 보겠습니다.
Y값은 y_true값이 되고 D는 y_pred값이 됩니다.

Contrastive loss에 대한 설명이 더 필요하신 분은 아래 논문을 읽어보시기 바랍니다.
Reference: Dimensionality reduction by Learning an Invariant Mapping
yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
이제 실제 코드로 구현해보겠습니다.
아래 우리가 구현한 contrastive_loss의 함수가 있고 아래 식을 그대로 코드화 하였습니다.
Y_pred^2은 K.square api를 사용하여 매개변수 y_pred를 제곱하여 줍니다.

max는 K.maximum api를 호출하고 margin은 하드코딩으로 1로 위에서 정해주었습니다. K.maximum(margin - y_pred, 0)의 값을 K.square에 넣어 제곱을 만들어 줍니다.

최종 식은 아래와 같이 구현되며 y_true 밑 y_pred의 각 요소에 대한 각 계산 결과의 전체 평균을 K.mean api를 사용하여 반환합니다.

여러분은 지난 시간에 배웠던 것처럼 model.compile의 loss를 function이름인 contrastive_loss를 넣어주면 됩니다. 정말 간단하죠?

지난 시간에 또 우리는 threshold를 model.compile의 매개변수로 넣어서 hyperparameter 튜닝을 할 수 있었습니다.
이번에는 margin을 가지고 한번 동일하게 만들어 보겠습니다.
단순하게 margin을 매개변수로 받는 wrapper function을 정의해 줍니다. (contrastive_loss_with_margin)
그리고 그 wrapper함수는 return으로 실제 동작해야 할 loss function의 이름을 넣어줍니다.

그다음 model.compile에서 loss에 wrapper function의 이름을 넣어주고 매개변수로 margin과 원하는 값을 설정해 주면 됩니다.

또한 우리는 Huber loss에서도 보았듯이 keras loss를 상속받아 클래스 형태로 loss를 정의할 수 있었습니다.
이 loss class는 무조건 init과 call function을 구현해야만 했습니다.
init은 margin 매개변수를 받아들이는 데 사용하였고 self.margin에 margin값을 저장합니다.
클래스 변수는 loss함수 내에서 self.margin으로 사용할 수 있습니다.

이 정의된 class loss는 역시 model.compile에 loss로 넣어주면 되고, margin 값을 조절하려면 매개변수로 넣을 때 margin값을 바꿔서 넣어주면 됩니다. 생성자가 호출될 때 이 값이 전달됩니다.

이번 시간은 contrastive loss를 함수 형태와, class 형태로 구현하는 법을 배워 봤습니다.
week2 강의는 이렇게 끝났습니다. 우리는 이제 custom loss를 쉽게 구현할 수 있게 되었습니다.
축하드립니다!!
300x250




댓글