본 포스팅은 다음 과정을 정리 한 글입니다.
Custom Models, Layers, and Loss Functions with TensorFlow
www.coursera.org/specializations/tensorflow-advanced-techniques
TensorFlow: Advanced Techniques
deeplearning.ai에서 제공합니다. Expand your skill set and master TensorFlow. Customize your machine learning models through four hands-on courses! Enroll for free.
www.coursera.org
지난 시간 Review
2021/03/07 - [Artificial Intelligence/Keras] - [Tensorflow 2][Keras] Week 1 - Branching models
Creating a Multi-Output model, Multi-Output code walkthrough, Multi-output
이번 시간에는 여러 아웃풋을 가지는 모델을 만들어 보려고 합니다.
아래 데이터는 UCI에서 제공하는 Energy efficiency Data Set입니다. 이 데이터를 가지고 한번 놀아보겠습니다.

이 데이터는 8개의 Feature들과 2개의 Label로 구성되어 있습니다. 이 데이터를 가지고 Y1과 Y2 각각의 model을 만드는 대신 한번에 두개의 multi output 모델을 만들어 보겠습니다.
우리는 Y1의 output 예측하기 위해서 또 다른 layer가 필요할 수도 있습니다. 또한 Y2 output을 예측하기 위해서도 다른 layer가 필요할 수도 있습니다.
그러면 한번 model을 구성해보도록 하겠습니다.

우리는 먼저 InputLayer에 8개의 Feature를 입력으로 받습니다. 데이터의 갯수가 몇개인지 모르기 때문에 일단 [(?,8)]로 되어있습니다. 만약에 데이터가 1000개이면 [(1000,8)]이 input이 되겠죠!! output도 마찬가지구요. 그대로 input을 받아서 output으로 내보내는 Layer이기 때문입니다.
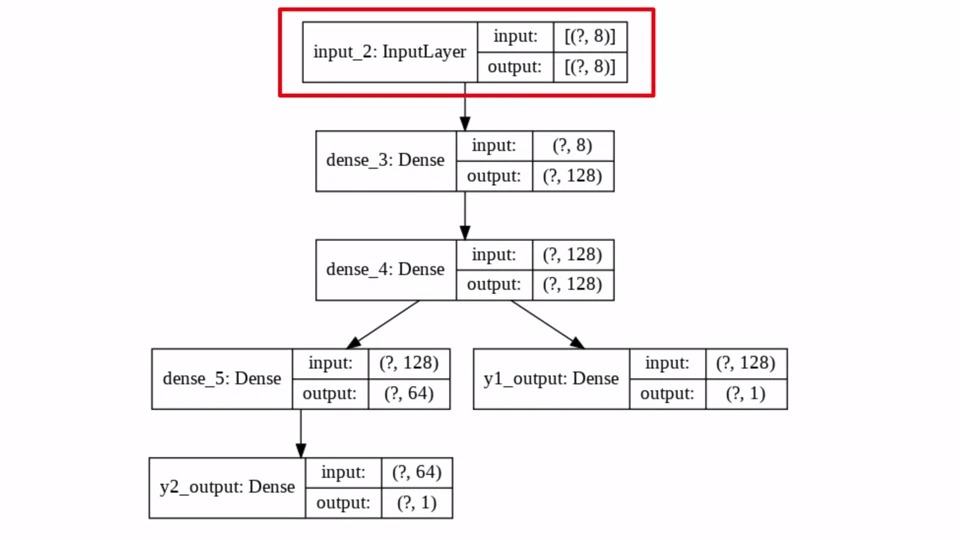
그 다음 연결되는 2개의 Dense Layer는 128개의 뉴런을 가지고 있습니다. 그렇기 때문에 (?,128)이 되는 것입니다. InputLayer로부터 (?,8)을 받았으니 dense_3의 input은 그대로 (?,8)이 되는 것이구요
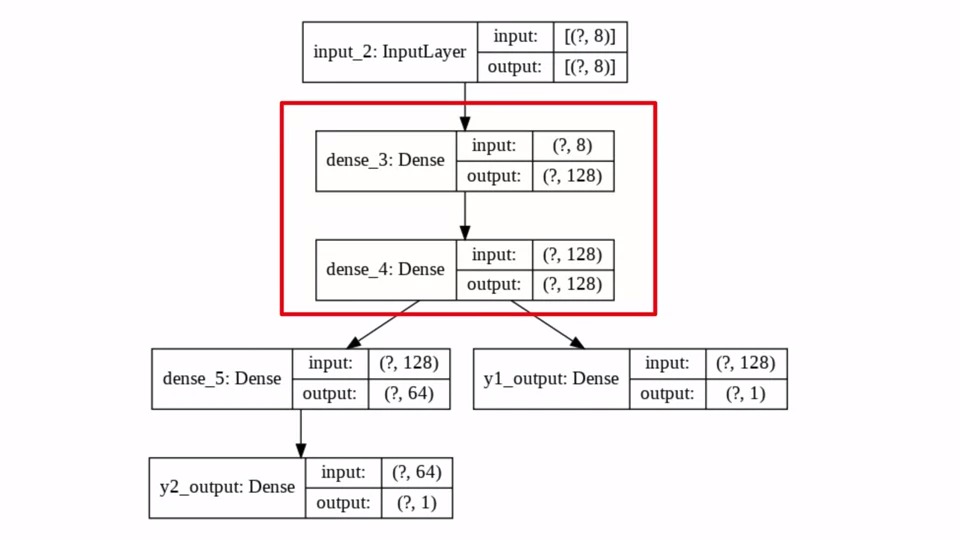
dense_4 이후로 Layer가 분기 된 것을 볼 수 있습니다. y1_output은 dense_4 layer로 부터 input을 받아서 그대로 (?,1) 의 output을 내보내고 있습니다.
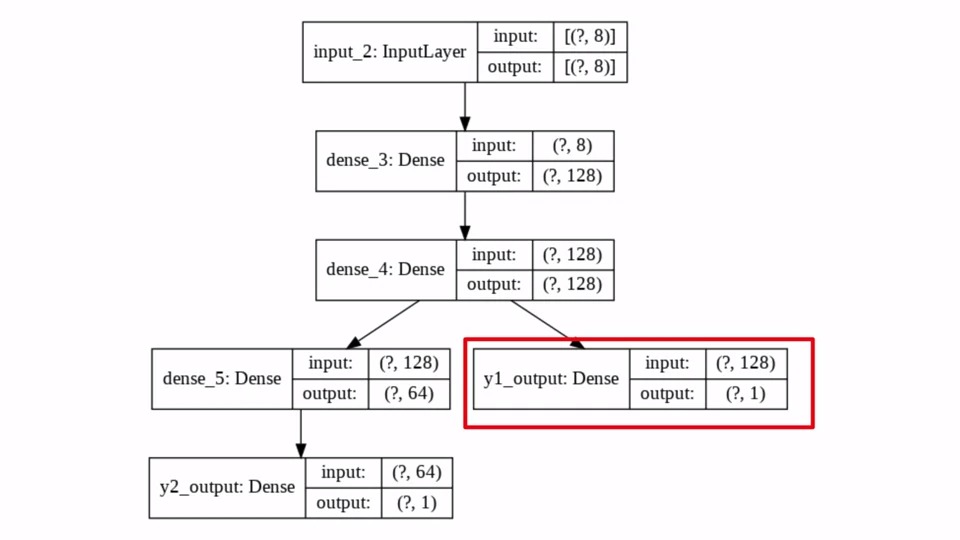
반면에 다른 분기점은 dense_4로부터 input을 받아 output을 (?,64)로 만드는 Dense(64)의 Layer와 연결되어 있습니다. y2_output은 dense_5로부터 input을 받아서 (?,1)의 output을 만들어 내고 있습니다.
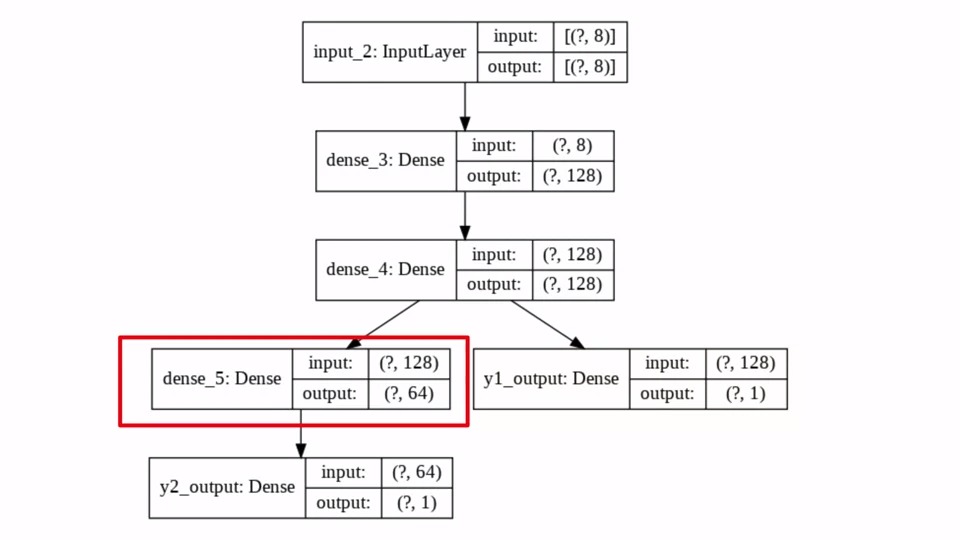
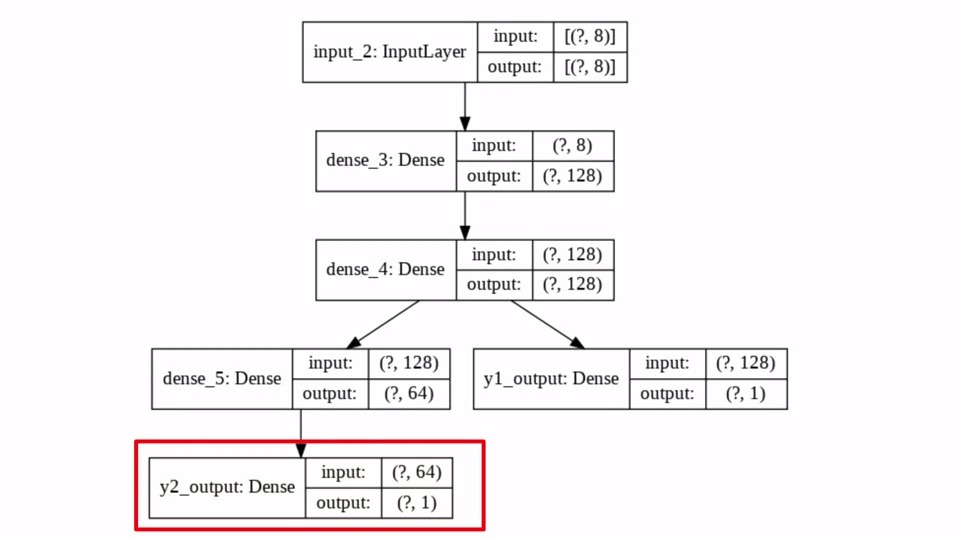
이렇게 single model로 multiple output을 예측하는 모델을 만들어 봤습니다.
이번에는 코드로 한번 살펴보겠습니다.
아래 그림은 구조를 시각화한 것입니다.
keras에서는 각 layer에 이름과 숫자를 기본적으로 부여합니다. dense_3, dense_4처럼 말입니다.
만약에 여러분이 모델에 이름을 부여하면 여러분이 부여한 이름이 layer의 이름에 보여지게 됩니다.
먼저 input을 정의하고 shape으로 우리가 training하려는 데이터의 크기와 feature개수를 넣어줍니다.

그 다음 first_dense를 Dense layer에 뉴런이 128개이고 activation function은 relu라고 선언합니다.

마찬가지로 second_dense도 128개의 뉴런과 activation function을 relu로 선언합니다.

여기서 부터 분기가 되는데 y1_output을 Dense Layer, 뉴런을 1개, 이름을 y1_output으로 정해줍니다. 아까 이름을 정하면 그 것으로 이름이 바뀐다고 말씀드렸는데 그래서 오른쪽 모델 시각화에 Dense 왼쪽에 y1_output으로 바뀌어 있는 것을 알 수 있습니다. 이전 layer는 second_dense이므로 (second_dense)를 넣어줍니다.

그 다음 y2를 정의하기 위해 third_dense를 64개의 뉴런과 activation function을 relu로 정의하고 (second_dense)를 이전 layer로 연결해 줍니다.
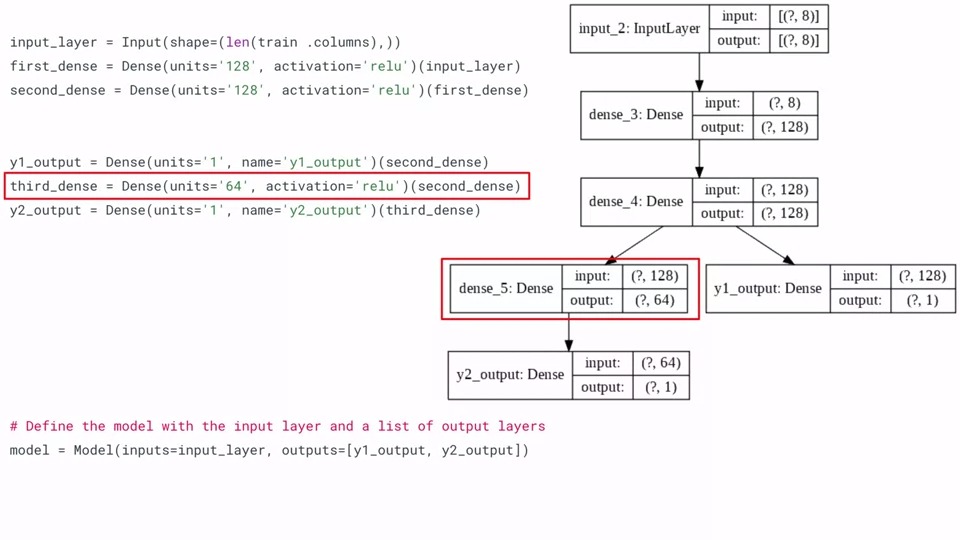
y2_output을 Dense Layer, 뉴런 1개, 이름을 y2_output으로 하고 (third_dense)와 연결해 주면 됩니다.
별거 아니죠?!
마지막에 모델을 정의하는데 inputs는 1개이므로 input_layer를 넣어주고, outputs는 두개이므로 [y1_output, y2_output] 으로 선언해주면 완성이 됩니다.

그럼 실제 코드로 한번 돌려볼까요?
먼저 Import를 해야됩니다!!
Import
#Tensorflow 2.x인지 확인
try:
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input
from sklearn.model_selection import train_test_splitUtilities (도구들)
We define a few utilities for data conversion and visualization to make our code more neat.
데이터 변환과 시각화를 위한 몇가지 도구들을 정의함
def format_output(data):
y1 = data.pop('Y1')
y1 = np.array(y1)
y2 = data.pop('Y2')
y2 = np.array(y2)
return y1, y2
#데이터 평준화 함수
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
#정답과 예측값의 diff를 그림
def plot_diff(y_true, y_pred, title=''):
plt.scatter(y_true, y_pred)
plt.title(title)
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.axis('equal') #각 축의 범위와 축의 스케일을 동일하게 설정
plt.axis('square') #각축의 범위 즉 xmax-xmin-ymax-ymin 되도록 설정
plt.xlim(plt.xlim()) #x축의 제한 설정
plt.ylim(plt.ylim()) #y축의 제한 설정
plt.plot([-100, 100], [-100, 100]) #y=x선을 그음
plt.show()
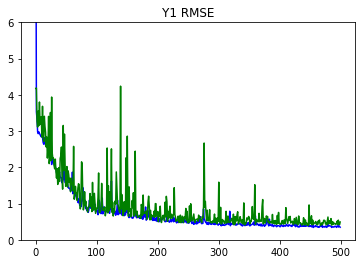
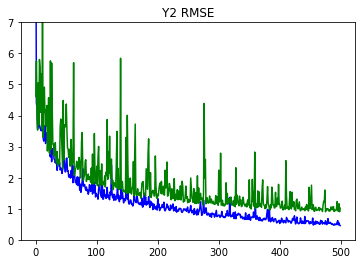
def plot_metrics(metric_name, title, ylim=5):
plt.title(title)
plt.ylim(0, ylim)
plt.plot(history.history[metric_name], color='blue', label=metric_name)
plt.plot(history.history['val_' + metric_name], color='green', label='val_' + metric_name)
plt.show()Prepare the Data (데이터 준비)
We download the dataset and format it for training.
학습을 위한 데이터셋과 포멧을 다운로드
# UCI 데이터 셋을 가져옴
URL = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00242/ENB2012_data.xlsx'
# pandas excel 함수 사용하여 excel 데이터를 가져옴
df = pd.read_excel(URL)
df = df.sample(frac=1).reset_index(drop=True)
# train과 test용 데이터를 train(80%) test(20%)로 나눔
train, test = train_test_split(df, test_size=0.2)
train_stats = train.describe()
# Y1과 Y2를 각각 np array로 만들어 train_Y, test_Y에 대입 (2개의 output)
train_stats.pop('Y1')
train_stats.pop('Y2')
train_stats = train_stats.transpose()
train_Y = format_output(train)
test_Y = format_output(test)
# train, test 데이터 정규화
norm_train_X = norm(train)
norm_test_X = norm(test)Build the Model (모델 만들기)
Here is how we'll build the model using the functional syntax. Notice that we can specify a list of outputs (i.e. [y1_output, y2_output]) when we instantiate the Model() class.
Functional syntax를 통해 모델을 만들었습니다. Model class를 인스턴스화 할때 [y1_output, y2_output] 이라는 outputs의 리스트를 지정할 수 있습니다.
# model layer정의
input_layer = Input(shape=(len(train .columns),))
first_dense = Dense(units='128', activation='relu')(input_layer)
second_dense = Dense(units='128', activation='relu')(first_dense)
# second dense에서 y1_output으로 연결
y1_output = Dense(units='1', name='y1_output')(second_dense)
# second dense에서 third_dense로 연결
third_dense = Dense(units='64', activation='relu')(second_dense)
# y2_output은 third_dense와 연결
y2_output = Dense(units='1', name='y2_output')(third_dense)
# input layer 와 output layer들로 Model을 정의
model = Model(inputs=input_layer, outputs=[y1_output, y2_output])
# 모델 요약 출력
print(model.summary())Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 8)] 0
__________________________________________________________________________________________________
dense (Dense) (None, 128) 1152 input_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 128) 16512 dense[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 64) 8256 dense_1[0][0]
__________________________________________________________________________________________________
y1_output (Dense) (None, 1) 129 dense_1[0][0]
__________________________________________________________________________________________________
y2_output (Dense) (None, 1) 65 dense_2[0][0]
==================================================================================================
Total params: 26,114
Trainable params: 26,114
Non-trainable params: 0
__________________________________________________________________________________________________
NoneConfigure parameters (매개 변수 구성)
We specify the optimizer as well as the loss and metrics for each output.
우리는 optimizer를 지정하고 또한 각각의 ouput을 위한 loss와 metrics도 지정해야 합니다.
# optimizer로 SGD를 사용하고 두 개의 output의 loss를 'mse', RootMeanSquareError로 metrics를 계산
# metric란 여러분이 만든 모델의 성능을 평가하기위해 쓰이는 함수입니다.
optimizer = tf.keras.optimizers.SGD(lr=0.001)
model.compile(optimizer=optimizer,
loss={'y1_output': 'mse', 'y2_output': 'mse'},
metrics={'y1_output': tf.keras.metrics.RootMeanSquaredError(),
'y2_output': tf.keras.metrics.RootMeanSquaredError()})metric의 자세한 설명은 아래 문서를 참고하세요.
Keras documentation: Metrics
Metrics A metric is a function that is used to judge the performance of your model. Metric functions are similar to loss functions, except that the results from evaluating a metric are not used when training the model. Note that you may use any loss functi
keras.io
Train the Model (모델 학습)
# 500 epoch 모델 학습 진행
history = model.fit(norm_train_X, train_Y,
epochs=500, batch_size=10, validation_data=(norm_test_X, test_Y))Evaluate the Model and Plot Metrics (모델 평가 및 매트릭스 Plot)
# 모델 테스트, 두개의 output의 loss와 mse 출력
loss, Y1_loss, Y2_loss, Y1_rmse, Y2_rmse = model.evaluate(x=norm_test_X, y=test_Y)
print("Loss = {}, Y1_loss = {}, Y1_mse = {}, Y2_loss = {}, Y2_mse = {}".format(loss, Y1_loss, Y1_rmse, Y2_loss, Y2_rmse))# loss와 mse 그리기
Y_pred = model.predict(norm_test_X)
plot_diff(test_Y[0], Y_pred[0], title='Y1')
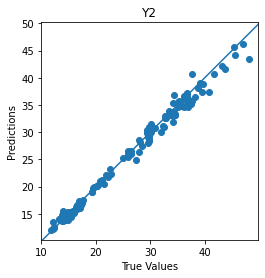
plot_diff(test_Y[1], Y_pred[1], title='Y2')
plot_metrics(metric_name='y1_output_root_mean_squared_error', title='Y1 RMSE', ylim=6)
plot_metrics(metric_name='y2_output_root_mean_squared_error', title='Y2 RMSE', ylim=7)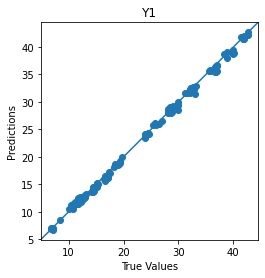
이번 시간은 이것으로 마치겠습니다.
감사합니다.
'Artificial Intelligence > Keras' 카테고리의 다른 글
| [Tensorflow 2][Keras] Programming Assignment: Multiple Output Models using Keras Functional API (0) | 2021.03.13 |
|---|---|
| [Tensorflow 2][Keras] Week 1 - Siamese Network (0) | 2021.03.13 |
| [Tensorflow 2][Keras] Week 1 - Branching models (0) | 2021.03.07 |
| [Tensorflow 2][Keras] Week 1 - Declaring and stacking layers (0) | 2021.03.05 |
| [Tensorflow 2][Keras] Week 1 - Introduction to the Functional APIs (0) | 2021.03.05 |



댓글